오늘 포스팅에서는 흔히 Read Committed 격리 수준에서 생기는 부정합 문제인 Non-Repeatable Read 문제를 해결하기 위해 사용하는 방법이라고 알려져있는 MVCC에 대해서 알아보도록 하겠습니다.
이 포스팅에서는 MVCC가 무엇인지, 사용하면 어떤 이점이 있는지, 동작원리 등을 알아볼겁니다.
MVCC에 대해서 깊게 알고싶지 않으신 분들은 그냥 Non-Repeatable Read 문제를 해결하기 위해서 Undo영역 혹은 Xmin, Xmax를 이용해 해결하는 방법론이라고 알고 계시면 될 것같습니다.
그럼 시작해보죠
MVCC란?
MVCC란 Multiversion Concurrency Control의 약자로 해석해보면 "여러개의 버전으로 동시성문제를 해결하는 방법"이라고 할 수 있습니다. 왜 굳이 방법이라는 단어를 붙였냐면 MVCC는 딱히 대단한 기술이나 기능이 아니고 방법론이기 때문입니다.
쉽게 예를 들어보자면 알고리즘과 같습니다. 알고리즘 중에 Two Pointers Algorithm 이라는 알고리즘이 있는데 개념은 두개의 포인터를 사용하여 배열에 접근하여 시간복잡도를 획기적으로 줄여주는 알고리즘입니다.
이 알고리즘을 구현하기 위해서 다양한 방법으로 코드를 작성할 것이고 설령 다르게 작성하였다고해도 본질만 같으면 상관 없는 것과 비슷합니다.
동시에 여러 트랜잭션이 조회와 변경을 필요로 할 때 데이터를 어떻게 안전하게 보호할 것인지에 대한 방법론이라고 생각해주시면 좋습니다.
DBMS에 굉장히 필수적인 기능이기 때문에 많은 데이터베이스에서 구현했고 다양한 구현 방법이 있습니다.
MVCC의 이점
MVCC의 이점은 다음과 같습니다.
- 데이터베이스 락이 필요로한 부분을 줄일 수 있다.
- 데이터베이스에 접근하기위한 contention을 줄일 수 있다.
- 읽기 성능을 항상시킬 수 있다.
- 쓰기작업에 대한 고립성을 보장해준다.
- 데이터베이스 데드락을 줄여준다.
짚고 넘어가야할 단어들이 몇개 보이네요. contention과 데드락에 대해서 간단하게 알아보도록 하죠
contention
사전적인 의미는 "논쟁"이지만 컴퓨터 사이언스에서는 다른 뜻으로 쓰입니다. 위키피디아에선 contention을 다음과 같이 설명하고 있습니다.
In Computer science, resource contention is a conflict over access to a shared resource such as random access memory, disk storage, cache memory, internal buses or external network divices.
아주 쉽게 풀어쓰자면 "메모리에 접근할 때 충돌하는 것" 정도로 해석할 수 있습니다. 충돌이라는 표현이 좀 어색하긴 하지만 메모리에 접근할 때 드는 리소스 정도로 해석하면 좋을 것 같습니다. 정확한 뜻은 모르더라도 느낌만 알면 됩니다.
contention은 이쯤하면 될 것 같습니다. 다음은 데드락에 대해서 알아보시죠
deadlock
데드락은 말그대로 락이 죽어버리는 것입니다. 동시성 문제에는 크게 두가지 문제가 있습니다. 가시성과 원자성문제이죠 가시성 문제는 volatile 키워드로 해결하고 원자성 문제는 synchronized 키워드로 해결합니다.
우리가 집중해서 봐야할 것은 이 원자성 문제를 해결하는 synchronized입니다. 스레드가 하나이상 메서드로 들어오는 것을 막아주는 키워드이죠.
근데 만약 요청하는 스레드가 너무 많아서 줄을 서고 있다면 어떨까요? 아니면 하나의 메서드 안에서 스레드가 돌고 돌고 돌고 계속 도는 상황이면요?
그 뒤에 있는 스레드가 기다리다못해 팍 하고 죽어버리는 상황이 생깁니다. 그러면 죽어버린 그 스레드 뒤의 스레드들은 차례대로 전부다 죽어버리는것이죠.
이 문제는 참 심각하죠. 이것이 바로 데드락입니다.
다시 MVCC로 돌아와서 MVCC가 개발되기 전 데이터베이스들은 전부 이 락을 가지고 여러 트랜잭션의 고립성을 보장했습니다. 하지만 말씀드렸다시피 데드락이 발생하기 딱 좋은 상황이 펼쳐졌습니다.
이러한 여러가지 이유로 MVCC가 개발되었고 이러한 문제들이 많이 줄어들었습니다.
MVCC의 동작원리
MVCC의 구현 방법은 앞서 말했듯이 한가지만 있는 것이 아닙니다. 하지만 보통의 상황에서 어떻게 동작하는지 알려드리도록 하겠습니다.
- 모든 데이터베이스 레코드별로 version number가 부여된다.
- 동시에 읽는 작업은 제일 높은 version number의 레코드에서 일어난다.
- 쓰기 작업은 원본 레코드가 아니라 복사된 레코드에서 실행된다.
- 유저는 복사본이 업데이트 되는 동안 오래된 버전에서 읽는 것을 계속한다.
- 쓰기 작업이 성공적으로 마무리된 후에 version number가 하나 증가한다.
- 이후 동시에 읽는 작업은 업데이트된 버전을 사용한다.
- 새로운 업데이트가 일어나면 새로운 버전은 다시 생성되고 이 작업이 반복된다.
우선 이렇게 동작하긴 하지만 글로 적으니 이해가 잘 안되시죠. 그림으로 한번 알아보도록 하겠습니다.
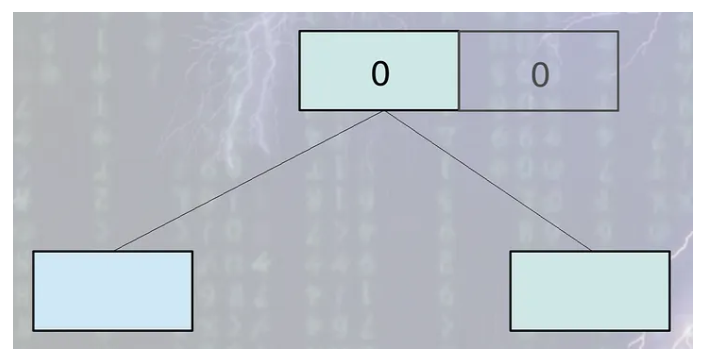
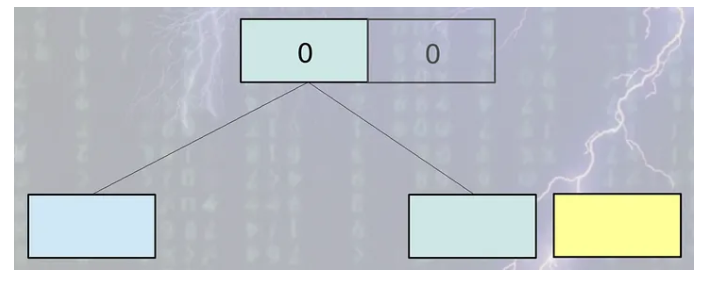


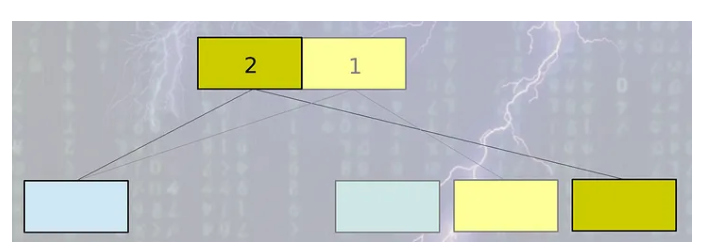
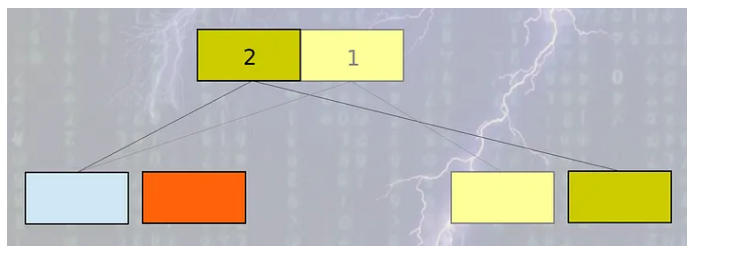
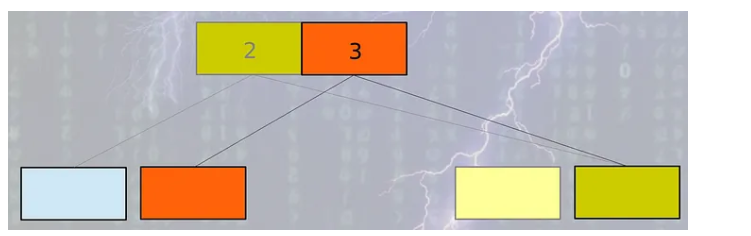
그림으로 보니까 좀 이해하기 편하시죠?
여태까지 너무 MVCC의 장점에 대해서만 서술한 것 같아서 단점에 대해서도 몇개 짚고넘어가겠습니다.
MVCC의 단점
- 동시다발적인 업데이트를 제어하는 방법이 구현하기 어렵습니다.
- MVCC를 사용하다보면 데이터베이스가 점점 커지고 부풀어 오르게 됩니다. = 데이터베이스가 점점 무거워집니다.
이러한 MVCC는 여러 데이터베이스에서 이미 구현해놨고 우리는 원리만 이해하면 됩니다. 여기서 알아두면 좋을 MVCC의 상식에 대해서 잠깐 말씀드릴게요. Oracle과 Mysql 데이터베이스는 Undo 영역을 두어 MVCC를 구현했고, PostgreSQL은 Xmin, Xmax를 기반으로한 Vaccum을 이용해 MVCC를 구현했습니다.
여기까지 MVCC에 대해서 알아봤습니다. 워낙 딥한 내용이니만큼 이해하기 참 어려웠던 것 같습니다. MVCC는 데이터베이스의 심화과정이기 때문에 면접에서 이렇게까지 깊게 물어보진 않을 듯 합니다.
하지만 이런 경우가 있을 수 있죠.
Q. 데이터베이스 격리수준에 대해서 말씀해주세요.
A. 데이터베이스 격리수준에는 Read Uncommitted, Read Committed, Repeatable Read, Serializable 이 있는데 (Read Uncommitted 생략) Read Committed는 Oracle이 기본적으로 사용하는 격리수준이고 Non-Repeatable Read 부정합 문제가 발생합니다. Repeatable Read 격리수준은 Non-Repeatable Read 부정합 문제를 해결했지만 Phantom Read 부정합 문제가 발생할 수 있습니다.
라고 답변한 상황에서 (물론 이것보다 더 자세하게 말씀하셔야합니다)
이런 꼬리질문이 들어올 수 있죠
Q. Oracle은 Non-Repeatable Read 부정합 문제를 어떻게 해결했나요?
혹은
Q. Mysql은 Phantom Read 부정합 문제를 어떻게 해결했나요?
라는 질문에 당당하게
A. Non-Repeatable Read 부정합 문제는 MVCC를 이용해 해결했고 Phantom Read 부정합 문제는 gap-locking으로 해결했습니다.
라고 대답할 수 있습니다. 여기서 더 깊게 물어볼 수 있습니다. MVCC가 뭐냐
그럴땐 MVCC는 동시성문제를 해결하기 위해 사용하는 방법론으로서 Oracle과 Mysql에서는 Undo 영역을 추가함으로써 구현하였고 PostgreSQL에서는 Vaccum을 이용해 구현했습니다.
자 이렇게 대답한다면 제가 면접관이면 기분이 참 좋을 것 같습니다. 엄청 깊게 공부했네? 하고 생각할 것 같네요.
제가 존경하는 개발자인 향로님(이동욱님)께서 이런 말씀을 하셨었죠. "뭐든 하나 공부하면 깊게 공부하세요. 그게 여러분의 무기가 될거에요"
자 여기까지 긴 글 읽어주셔서 정말 감사합니다. 다음 포스팅은 Phantom Read 부정합 문제를 해결하기 위해 등장한 gap-locking에 대해서 알아보도록 하겠습니다. 오늘도 즐거운 하루 되세요~
출처
What is MVCC? How multiversion concurrency control works
What is multiversion concurrency control? Multiversion concurrency control (MVCC) is a database optimization technique that creates duplicate copies of records so that data can be safely read and updated at the same time. With MVCC, DBMS reads and writes d
www.theserverside.com
https://kousiknath.medium.com/how-mvcc-databases-work-internally-84a27a380283
How MVCC databases work internally
In my previous article, I discussed some internals on storage techniques of different sort of databases. LSM tree, fractal tree & B-Tree…
kousiknath.medium.com
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| Phantom Read 부정합문제 해결방안 In PostgreSQL, MSSQL Server (0) | 2023.03.06 |
|---|---|
| Phantom Read 부정합문제 해결방안 In Mysql (0) | 2023.03.04 |
| 트랜잭션과 ACID (자바에서 트랜잭션을 다루는 방법에 대한 관점으로) (0) | 2023.02.27 |
| 커넥션 풀 (Connection Pool) (0) | 2023.02.27 |
| 데이터베이스 정규화 (0) | 2022.12.22 |