
개발놀이터
아파치 카프카 (개념) 본문
저번 포스팅에서 파트2를 시작하면서 메세지 브로커의 장을 열었습니다. 메세지 브로커를 이용해서 서버간 통신을 조금 더 매끄럽게 진행할 수 있다는 것을 알았고 어떤 모델이 있는지 알았습니다.
이번엔 Pub/Sub 메세징의 대표주자 아파치 카프카 (Apache Kafka) 에 대한 개념을 잡아보도록 하겠습니다.
구글 트렌드

위의 그래프는 구글 트렌드에서 검색한 Kafka와 RabbitMQ에 대한 트렌드 추이입니다.
기본적으로 Kafka에 대한 검색량이 높고 특징으로는 2022년에 들어오면서 갑자기 70퍼센트대로 올라왔다는 것이 눈에 띕니다.
이는 한국에서 보이는 추이이고 이번엔 글로벌로 보겠습니다.
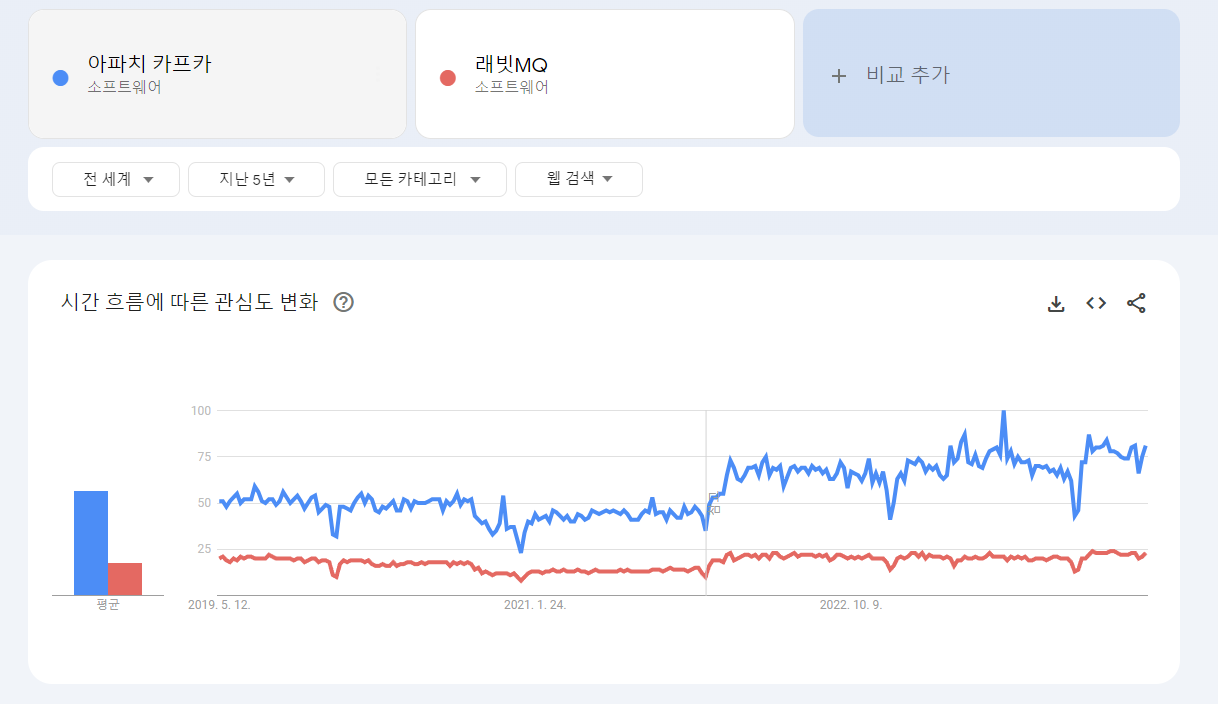
글로벌도 상황은 비슷해보이네요. 역시 2022년에 카프카에 대한 수치가 올라간 것이 특징입니다. RabbitMQ도 소폭 상승했네요.
여기에 Redis까지 넣으면 Redis는 Pub/Sub 메세징으로도 쓰이지만 캐싱으로 더 많이 쓰이기 때문에 혼란을 줄 우려가 있어 넣지 않았습니다.
이렇게 카프카가 많이 쓰이는 이유가 뭘까요? Pub/Sub 메세징이라서? 그 이유에 대해서 알아보도록 하죠.
Apache Kafka
카프카의 특징은 구글링해보시면 지겹도록 보실 수 있습니다. 비동기 통신을 지원한다느니 논블락킹 I/O라느니 복사 붙여넣기 한 수준으로 다 똑같은 내용을 포스팅해서 저는 그 내용은 넣지 않겠습니다.
저는 그럼 어떤 내용을 포스팅 할 것이냐.
바로 카프카에 대한 용어 완전 정복과 특징, 그리고 아키텍처를 얘기해볼까합니다.
카프카에서 사용하는 용어
카프카에서 주로 어떤 용어를 사용하는지 간단하게 개요를 확인하고 이후 예시를 통해 딥하게 들어가보도록 하겠습니다.
- producer or publisher : producer 혹은 publisher (이하 publisher)는 메세지를 보내는 주체입니다. 간단하게 "메세지 보내는 놈"이라고 생각하시면 편합니다.
- consumer or subscriber : consumer 혹은 subscriber (이하 subscriber)는 메세지를 받는 주체입니다. 간단하게 "메세지 받는 놈"이라고 생각하시면 좋습니다.
- topic : topic은 메세지를 소비하는 consumer (혹은 subscriber) 의 마빡에 붙여놓는 라벨입니다. 어떤 종류의 메세지를 소비할 것인지 구별해놓는 용도로 사용합니다. 일단 이정도로 설명하고 뒤에 예시에서 더 자세하게 설명하도록 하겠습니다.
- consumer group : consumer group은 consumer를 관리하기위한 더 큰 라벨입니다. consumer group은 카프카에서 관리하고 뒤에 설명할 로드 리밸런싱에 대해서 자주 등장하게 될 내용입니다.
- partition : partition은 메세지가 이동하는 하나의 queue라고 생각하시면 됩니다.
이제 하나씩 뜯어볼까요?
이 용어 중 중요한 것은 바로 topic입니다. 왜냐하면 다른 것들은 이해하기 쉬운데 topic은 직관적으로 이해하기 힘들거든요.
publisher, subscriber, topic, consumer group을 예시를 들어 설명해보겠습니다.
상황)
우리가 뉴스를 구독한다고 가정해볼까요? 저는 개인적으로 IT기사를 보는 편입니다. IT기사들이 올라오면 그때그때 알람을 받으면 좋죠.
기자가 뉴스 기사를 쓰고 수많은 기자분들 중에 IT 뉴스 기사를 쓰시는 분이 있으면 작성과 동시에 저한테 알람이 올겁니다. 이는 우리 생활에 흔히 있는 일이죠.
상황은 끝입니다. 이 두 문단으로 publisher, subscriber, topic, consumer group을 다 설명했습니다.
이제 하나씩 매치업해보면서 용어를 이해해봅시다.
- publisher는 기자입니다. 뉴스 기사를 쓰는 사람이죠.
- subscriber는 저 자신입니다. 뉴스 기사를 받는 사람이죠.
- topic은 IT 뉴스입니다.
- consumer group은 뉴스입니다.
자 이렇게 하면 이해하시기 편할겁니다.
publisher는 기자입니다. 뉴스 기사를 쓰는 사람인데 publisher는 특정 subscriber 즉 특정 구독자를 향해서 뉴스 기사를 쓰는게 아닙니다.
기자가 저만을 위해서 뉴스 기사를 쓰는게 아니라는 말이죠. 수많은 기자들 중 특정 topic으로 기사를 씁니다. 즉, publisher는 topic만 알고 누구한테 이 뉴스 기사가 소비되는지 모릅니다.
subscriber는 저 자신이죠. 구독자는 특정 topic만 구독해놓습니다. 그럼 그냥 저절로 topic에 해당하는 뉴스기사가 저한테 옵니다. 저는 어떤가요? 누가 썼는지 관심이 없죠. 그냥 IT 뉴스 기사이기만 하면 됩니다.
topic은 IT뉴스, 경제뉴스, 정치뉴스, 스포츠뉴스 이런식으로 각 주제를 이야기합니다. 구독자는 이 topic만 구독할 뿐이죠. 즉, topic은 publisher가 생성한 메세지가 어떤 subscriber로 갈지 정합니다.
카프카는 consumer group이라는 정보를 바탕으로 consumer 즉 메세지 소비자들을 구분해놓습니다.
이렇게 구분해놓으면 뭐가 좋을까요? 어디로 어떤 메세지가 가는지 라벨링을 해놓을 수 있습니다. 그럼 카프카 입장에서도 관리하기 편하겠죠?
이를 그림으로 설명해보겠습니다.
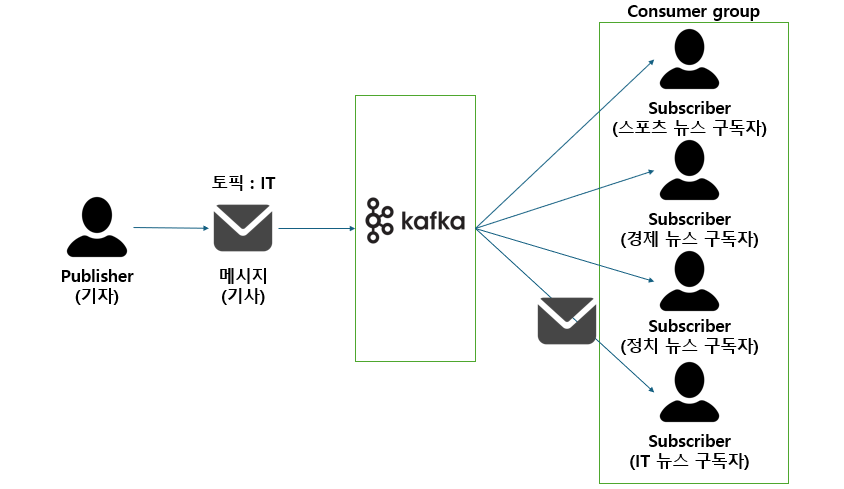
이 그림은 카프카의 아키텍처를 간단하게 도식화한 것입니다.
제가 partition에 대한 설명은 생략했는데, 카프카에서 각 subscriber로 이어지는 이 선들이 하나의 partition이라고 보시면 됩니다. 메세지가 이동하는 통로 내지는 queue라고 보시면 됩니다.
partition의 특징으로는 하나의 partition은 하나의 subscriber를 가집니다. 반드시!
반대로 subscriber는 "하나 이상"의 partition을 가질 수 있죠. 즉 1:N관계이지만 0...1이 아닌 그냥 1입니다. 0일수는 없습니다. 이 관계는 바로 직후에 이야기할 로드밸런싱과 장애회복에서 주요한 내용이 됩니다.
이제 카프카에서 주로 사용하는 용어에 대해서 대략적인 이해가 있으니 카프카의 주요한 특징에 대해서 알아보도록 하겠습니다. 바로 장애회복과 로드밸런싱입니다.
상황)
우리의 서비스는 주문과 결제 서버를 가지고 있습니다. 한번 상황을 가정해보도록 하죠.
*주문
서버 : 2대
consumer group : Order
topic : CustomerOrder
consumer : C1, C2 (C1, C2는 각각의 서버이자 메세지를 처리하는 consumer가 됩니다. 위에선 subscriber라고 했지만 여기서 consumer group이라는 이름을 위해 consumer로 통일하겠습니다.)
partition : P1, P2 (각 파티션은 숫자에 맞는 consumer와 연결되어있습니다.)
*결제
서버 : 2대
consumer group : Payment
topic : CustomerPayment
consumer : C3, C4 (이하 동일)
partition : P3, P4 (이하 동일)
장애회복
카프카에는 장애상황에 대처할 수 있는 능력을 가지고 있습니다. 예를 들어서 이런 상황을 가정해보도록 하죠.
상황속 상황)
갑자기 주문이 몰려 주문 서버 한대가 죽어버렸다.
이때 생기는 문제는 뭘까요?
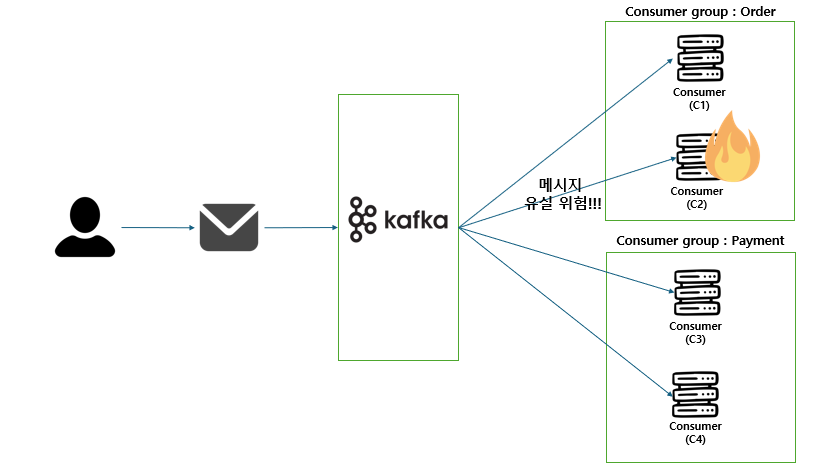
메세지가 유실되면 publisher가 보낸 데이터는 날아가게 되고 아무런 응답도 받지못해 붕뜬 상태가 될 수 있습니다.
주문을 위해 주문요청을 넣었는데 아무런 응답이 없게 되는것이죠.
이걸 조금 더 단순화하면 다음과 같습니다.
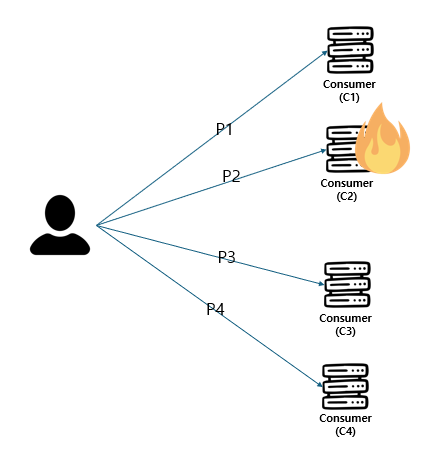
이 상황에서 카프카는 장애가 난 서버에게 가는 partition을 즉시 살아있는 다른 consumer group에 붙입니다. 즉, partition이 통합되는 것이죠.
이제 위의 상황은 장애시 이렇게 바뀌게 됩니다.
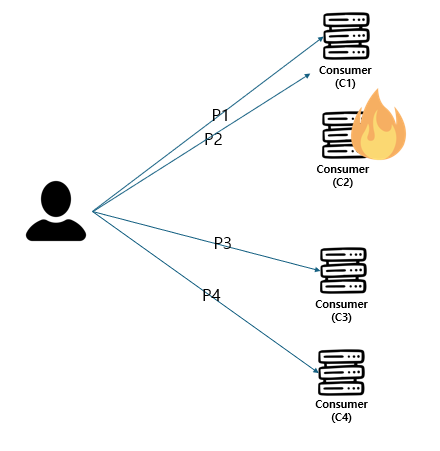
이렇게 바뀜으로써 장애상황에 안전하게 대응할 수 있게 됩니다.
이런 장애상황에 즉시 partition을 리밸런싱할 수 있는 이유는 바로 consumer group이 있기 때문입니다. consumer group은 groupId로 관리하는데 이 groupId를 보고 즉시 다른 consumer로 partition을 할 수 있는 것이죠.
로드밸런싱
메세지 브로커도 엄밀히 따지면 하나의 서버이고 때문에 이 미들웨어 서버로 들어오는 메세지들을 각기 다른 consumer에게 전달하는 것은 일종의 로드 밸런싱으로 보일 수 있죠.
하지만 카프카의 로드밸런싱은 조금 다릅니다.
상황속 상황)
우리는 장애 상황을 한번 맛본 뒤로 확장성의 필요성을 깊이있게 깨달았습니다. 우리 서비스가 커짐에 따라 결제는 괜찮은데 주문 서버가 좀 힘들어합니다. 그래서 우리는 고심끝에 주문 서버를 네대로 증설하기로 결정했습니다.
이제 상황은 이렇게 바뀌었습니다.
*주문
서버 : 4대
consumer group : Order
topic : CustomerOrder
consumer : C1, C2, C5, C6
partition : P1, P2, P5, P6
*결제
서버 : 2대
consumer group : Payment
topic : CustomerPayment
consumer : C3, C4
partition : P3, P4
이 상황에서 카프카에게 파티션이 늘어났음을 알려줘야합니다. 이는 카프카의 설정에서 바꿔줄 수 있습니다. 기존 partition을 두개에서 네개로 늘려주면? 카프카가 늘어난 consumer의 groupId를 보고 해당 consumer group으로 늘어난 partition 두개를 새로 편성해줍니다.
아키텍처 설계 with 클라우드
우리는 카프카의 장애회복과 로드밸런싱을 이용해서 안전하게 서비스를 운영할 수 있게 되었습니다. 하지만 사장님이 매우 화나신 것 같네요.
사장님 : 아니 지금도 서버 비용이 만만치않은데 서버를 두대나 늘리겠다고? 그 돈은 땅파면 나오나?
음... 맞는 말입니다. 트래픽을 분석해보니 주문이 폭주하는 시간대는 오후 7시에서 9시사이이고 다른 시간에는 평범하게 서버 두대로도 수용가능할 것으로 보입니다.
이걸 클라우드 아키텍처로 설계해봅시다.
이 내용은 실습에서 한번 해볼 예정이라 간단하게 개요만 설명하도록 하겠습니다.
준비물
- ECS or EKS : 서버를 유연하게 증설하고 폐기할 수 있는 시스템인 ECS와 EKS를 준비합니다. (저는 실습에서 ECS fargate를 이용할 예정입니다.)
- ASG : ECS와 EKS가 어떤 서버를 늘려야하는지 알 수 없으므로 Auto Scaling Group을 이용해서 EC2 인스턴스를 준비해둡니다.
- Cloud Watch Event and Lambda : 서버의 CPU 사용률이 90퍼센트가 넘으면 이를 감지하고 다른 서비스로 전파해주는 역할이 필요합니다. Cloud Watch Event를 이용해서 CPU의 사용량을 모니터링하고 90퍼센트가 넘으면 Lambda로 API를 보내도록 해야합니다.
- EC2 : 그냥 서버죠 뭐... 적당한 사양으로 준비해줍니다.
- API : 이 API는 카프카의 설정을 바꿔주는 API입니다. partition은 수동으로 늘려줘야하기 때문에 이 API를 받으면 카프카의 partition을 두개에서 네개로 늘려줍니다.
자 이제 준비물은 끝났습니다.
상황속 상황)
오후 7시가 되고 CPU사용량이 점점 늘어납니다.
60퍼...70퍼...80퍼...90퍼!!!
Cloud Watch가 서버의 CPU 사용량이 90퍼센트가 넘었다는 알람을 보내면서 Lambda를 호출합니다.
Lambda는 카프카의 partition을 네개로 변경하는 API를 호출함과 동시에 ASG에 트리거를 작동시킵니다.
카프카의 partition이 네개가 되면서 주문 서버의 groupId인 Order를 확인하고 partition을 새로 증편해줍니다. 동시에 ASG가 ECS의 클러스터와 인스턴스를 증가시키면서 서버를 두대 증설합니다.
오후 10시가 되어서야 서버의 CPU가 30퍼센트 아래로 내려가면서 상황은 종료됩니다.
서버의 CPU가 30퍼센트가 되면서 Cloud Watch Event가 발동되고 Lambda를 호출하여 카프카의 partition을 다시 두개로 줄여주는 API를 호출합니다.
동시에 ECS는 CPU가 30퍼센트가 된 것을 보고 서버 두개를 폐기해버립니다.
이를 그림으로 표현하면 다음과 같습니다.
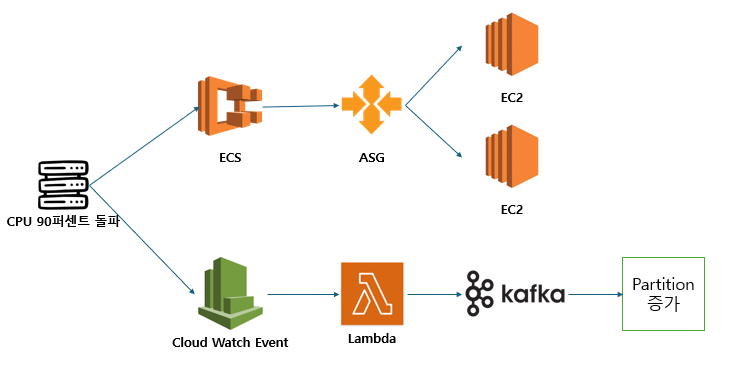
이왕 그리는김에 클라우드 아키텍처도 한번 볼까요?
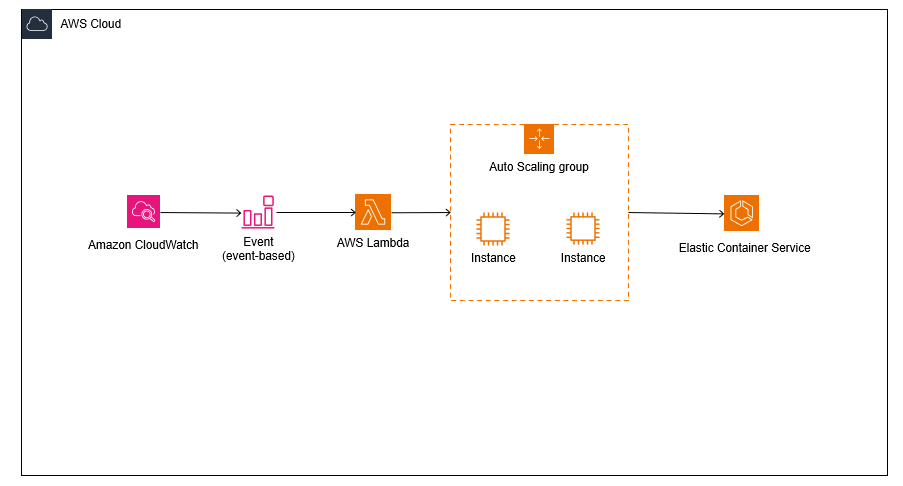
여기서 카프카를 SQS로 바꿀 수도 있을 것 같은데... 이 부분은 일단 카프카를 실습해보고 실험해보겠습니다.
마치며
이렇게 카프카의 용어인 publisher, subscriber, topic, consumer group, partition에 대해서 알아보고 카프카의 특징인 로드밸런싱과 장애회복도 알아봤습니다.
그리고 이후 실습으로 이 아키텍처가 가능한지 테스트도 해볼 예정입니다.
다음 포스팅에선 카프카를 가지고 실제로 실습을 해보도록 하겠습니다.
'Spring > Spring' 카테고리의 다른 글
| 스프링으로 영상 랜더링하기 (Resource Range) (0) | 2024.06.14 |
|---|---|
| JWT 중복로그인 방지 (0) | 2024.06.10 |
| 개발 하다 보면 많이 접하는 스프링 빈 직접 등록하기 : 활용편 (0) | 2024.05.15 |
| Spring Actuator (1) | 2023.07.18 |
| 프록시패턴, 데코레이터 패턴 (0) | 2023.06.27 |


