이번 포스팅에선 리눅스가 어떻게 파일을 읽고 쓰는지에 대해서 공부해본 내용을 정리하려합니다.
요즘 리눅스 커널에 대해서 공부하고있는데요. 아직 배경지식이 전무하다시피해서 공부하는데 애먹고있습니다. 바로 시작해보죠!
cf) 이 포스팅 전 읽고 오시면 좋은 글이 있습니다! 파일시스템에 대한 간략한 정보들이 정리되어있습니다.
https://coding-review.tistory.com/564
리눅스 기본 명령어 동작 원리 : 디렉토리 구조편 (cd, ls, rm, mv, cp)
이번 포스팅은 이전 포스팅에서 영감을 얻었습니다. https://coding-review.tistory.com/563 데이터베이스 쿼리를 실행하면 내부적으로는 어떤 일이 벌어질까?오랜만에 포스팅을 쓰는 것 같습니다. 거
coding-review.tistory.com
파일 입력
0. 사전 지식
- directory entry : 하나의 디렉토리안에 있는 파일이름, inode 번호같은 간단한 정보들이 적혀있는 메타데이터입니다.
- inode : 파일에 대한 조금 더 자세한 정보가 적혀있는 노드 (얘도 결국 메타데이터입니다) 입니다.
- data block : 데이터들이 저장되어있는 공간입니다. 이 공간을 이용해서 데이터를 이곳저곳 나르기도 하고 데이터들이 담겨서 이동하는 박스라고 생각하시면 됩니다.
1. 명령어 입력
다음과 같은 명령어가 입력되었다고 가정해보겠습니다.
$ echo "hello world" > hello.txt
이렇게 입력되는 순간 리눅스 커널은 System Call을 호출하는데 open()과 write()를 순서대로 호출합니다.
open()이 직관적으로는 파일을 연다는 느낌인데 파일을 저장할 때는 여는 것이 하나도 없어서 저는 그냥 파일시스템의 자원을 획득한다고 이해하고 있습니다. 이게 만약 잘못된 이해라면 댓글로 알려주시면 감사하겠습니다.
그렇게 이해하게된 이유가 파일을 출력할 때 read()라는 System Call을 호출하는데 그 전에도 open()을 호출하더라구요. 그리고 항상 파일시스템의 자원을 돌려주는 역할인 close()를 호출하는 것을 보면 자바에서도 파일 입출력을 할 때 스트림을 열고 닫는 것과 비슷해서 그렇게 이해했습니다.
아무튼!
System Call이 호출되면 커널 모드로 진입하게 되고 커널 모드에서 시스템 자원에 접근하게 됩니다. 이 때 시스템 자원인 파일시스템에 접근하게 되는데요, 파일 시스템은 먼저 프로세스에 접근해 현재 프로세스가 어떤 디렉토리에 들어와있는지 확인합니다.
2. directory entry, inode 생성
현재 디렉토리에 있는 directory entry에 지금 저장할 파일에 대한 directory entry를 적어놓습니다.
directory entry에는 파일에 대한 간략한 정보들이 적혀있는데요. 파일 이름이나 inode의 번호등이 적혀있습니다. inode의 번호는 어떤 inode를 바라보면 좋을지 포인터 형태로 되어있습니다.
directory entry는 간단하게 얘기하자면 inode들이 모여있는 배열이라고 할 수 있겠네요. 물론 진짜 배열인지는 모르겠지만요...
지금 저장하려는 파일의 이름을 적고 새로운 inode 번호를 부여받습니다. 그리고 이후 inode에 정보를 작성하죠.
inode에는 권한, 타임스탬프, UID, GID, 파일 크기 등등 파일에 대한 자세한 정보가 적혀있습니다. 이런 메타데이터들을 먼저 저장하고 실제 데이터를 저장할 준비를 합니다.
3. data block 생성 그리고 저장
파일시스템은 hello.txt의 실제 데이터인 "hello world"를 저장하기 위해 파일 크기만큼의 데이터 블록을 할당시켜놓습니다. 이렇게 할당함과 동시에 inode는 hello.txt의 실제 데이터가 저장될 공간을 포인터로 가리킵니다.
이후 hello.txt의 실제 데이터들이 데이터 블록에 담겨서 메모리에게 전달됩니다. 그리고 메모리는 이 데이터 블록에 담긴 실제 데이터를 그대로 스토리지 디바이스로 가져갑니다.
파일시스템이 storage controller를 호출해서 물리적으로 저장할 공간을 찾아 그곳에 실제 데이터를 저장합니다.
4. 사후처리
이후 inode에 최종적으로 저장된 파일 크기, 변경된 타임스탬프 등을 업데이트합니다.
또한, 파일시스템에 캐시를 업데이트해서 파일시스템이 관리하는 파일이라는 것을 명시하죠. 이 작업이 끝나고 나서야 우리 눈에 ls 명령어로 파일이 보이게 됩니다.
파일 출력
단순히 ls 명령어를 입력한다고 해서 파일이 출력되는 것은 아닙니다.
ls 명령어는 단지 현재 디렉토리의 directory entry를 가져와서 파일 이름만 뿌려줄 뿐이죠. 그럼 실제 데이터를 가져오는 명령어는 뭐가 있을까요?
vim을 이용해서 파일을 여는 작업이 실제 데이터를 가져오는 명령어입니다.
우리는 vim 명령어를 날려보고 이 vim 명령이 어떻게 파일을 읽는지 알아보려합니다.
1. 명령어 입력
만약 이런 명령어를 날린다고 가정해보겠습니다.
$ vim hello.txt
그럼 리눅스 커널은 open(), read()라는 System Call을 호출합니다. 그럼 이후 커널모드로 진입해서 실제 데이터를 가져오기위한 작업을 진행합니다.
2. 파일시스템 호출
커널모드로 진입한 프로세스는 파일시스템에 접근해서 해당 파일의 directory entry 안에 존재하는 파일 이름과 inode 번호를 조회합니다.
그리고 파일 이름과 매칭되는 inode 번호를 찾아서 inode를 바라보죠. 그럼 거기에 각종 메타데이터들이 적혀있는데 그 중에서 실제 데이터가 위치한 곳을 가리키는 포인터를 찾아냅니다.
이 포인터를 이용해서 실제 데이터가 어디에 위치하고 있는지 알 수 있는데요. 즉 리눅스는 이런 구조를 가지고 있는 것이죠.
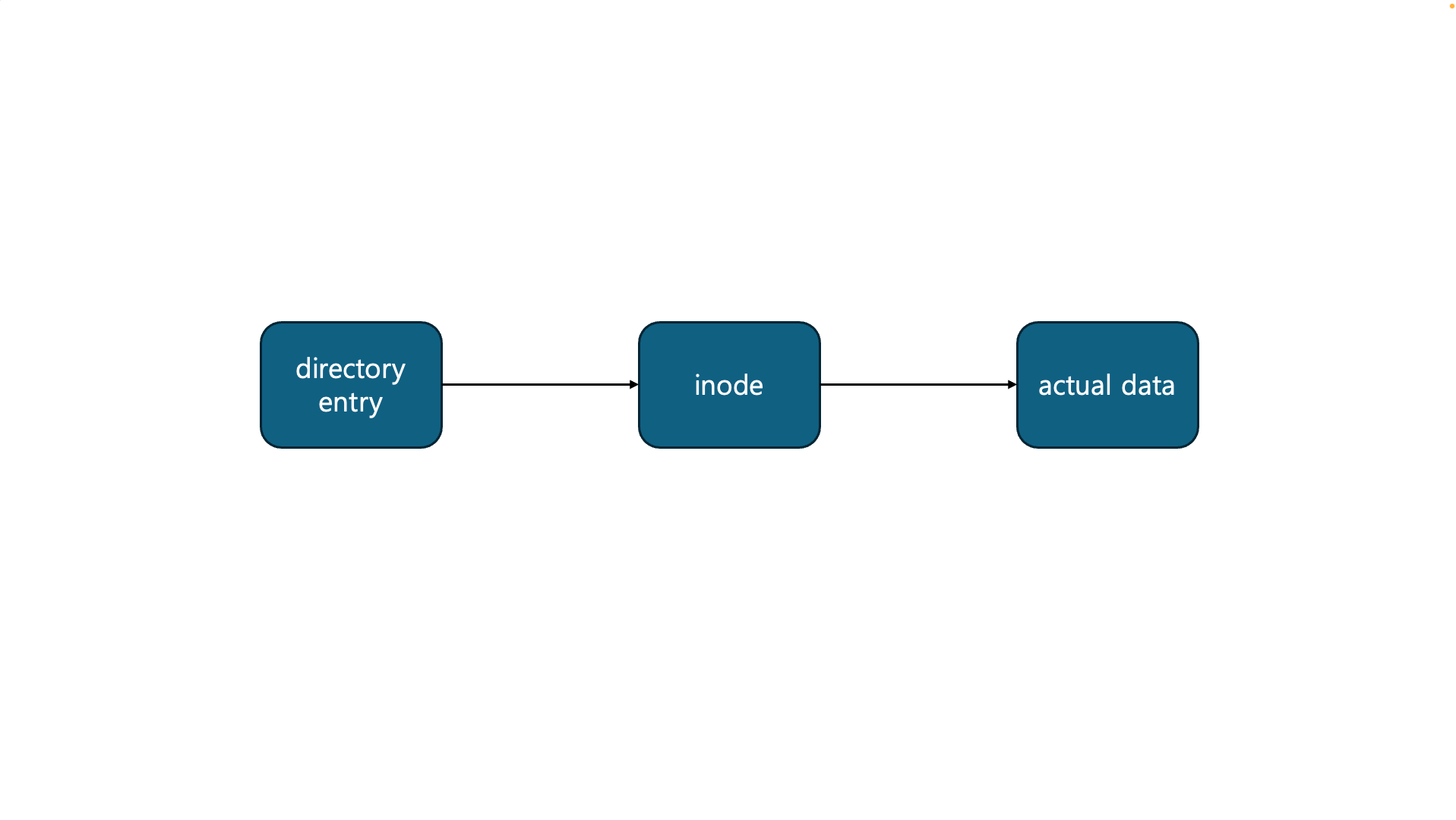
그럼 실제 데이터가 어딨는지 아니까 그 정보를 그대로 I/O Scheduler에게 전달합니다.
3. I/O Scheduler 호출
I/O Scheduler는 스토리지 디바이스에서 파일을 직접 가져올 때 사용됩니다. 파일시스템에게 전달받은 실제 데이터의 위치를 이용해서 storage controller를 호출하기 때문이죠.
만약 데이터베이스와 같이 많은 양의 데이터를 가져와야할 때는 스케줄러가 큰 의미가 있지만 단순 파일 입출력에서의 스케줄러는 그냥 storage controller에게 명령하는 존재일 뿐이죠.
스케줄러가 storage controller에게 데이터를 가져오라는 명령을 주면 storage controller는 HDD의 경우 헤드를 물리적으로 움직이는 seek를, SSD의 경우 실제 데이터를 가져오는 전기적 신호를 전달합니다.
4. 메모리에 적재 후 전달
스토리지 디바이스와 메모리 사이에는 DMA라는 친구가 숨어있습니다. Direct Memory Accessd의 약자로 이름에서 유추할 수 있듯이 스토리지 디바이스가 직접 메모리에 접근할 수 있도록 도와주는 친구입니다.
이 DMA의 존재 덕분에 CPU가 일일히 스토리지와 메모리를 컨트롤하지 않아도 되기 때문에 성능이 최적화되어 있습니다.
storage controller가 가져온 데이터를 메모리에 적재하고 이 메모리에 적재된 데이터를 커널에게 전달합니다. 그럼 이 커널은 커널모드에서 유저모드로 전환한 뒤 우리에게 실제 데이터를 보여주는 것이죠.
마치며
이번 포스팅에선 리눅스의 파일 입출력이 어떤 과정을 가지고 있는지 공부해보고 정리해봤습니다. 리눅스 커널에 대한 공부를 하면 할 수록 컴퓨터를 더 잘 이해하게 되는 것 같아서 뿌듯하고 좋네요.
항상 공부를 할 때 느끼는 벅차오르는 뿌듯함이 저로하여금 계속 공부할 수 있는 원동력을 주는 것 같네요. 이런 변태같은 지식들이 저를 더 뿌듯하게 만드니 더욱 더 공부해야겠다는 생각입니다.
여기까지 포스팅 마치도록 하겠습니다. 긴 글 읽어주셔서 감사합니다. 오늘도 즐거운 하루 되세요!
'CS 지식 > 운영체제' 카테고리의 다른 글
| CPU는 어떻게 여러가지 일을 한번에 처리할까? (0) | 2025.08.08 |
|---|---|
| TCP 프로토콜을 OS레벨에서 뜯어보자 (0) | 2024.11.11 |
| 리눅스 기본 명령어 동작 원리 : 디렉토리 구조편 (cd, ls, rm, mv, cp) (0) | 2024.10.29 |
| 데이터베이스 쿼리를 실행하면 내부적으로는 어떤 일이 벌어질까? (0) | 2024.10.27 |
| 리눅스 alias로 파일, 폴더 휴지통으로 이동시키기 (0) | 2024.06.06 |