만약 캐싱 솔루션으로 Redis를 사용하고 있다면 Redis가 장애상황으로 죽어버리는 경우 RDBMS에 부하가 심하게 발생하여 RDBMS까지 연쇄적으로 장애가 발생하는 상황이 충분히 있을 수 있습니다.
저는 프로젝트를 진행하면서 Redis를 이용해서 캐싱 솔루션을 도입했고 결과적으로 RDBMS의 부하를 30퍼센트 이상 줄이기도 하였습니다.
이 30퍼센트라는 수치는 결코 무시할 수 없기 때문에 Redis의 장애상황에 대한 대비책이 있어야합니다.
이번 포스팅에선 Redis가 장애시 RDBMS의 연쇄적인 장애를 대응하기 위해 어떤 전략을 사용하는지 알아보도록 하겠습니다.
Redis의 가용성을 높이자!
흔히 생각할 수 있는 방법으로 Redis를 죽지않게 관리하는 것입니다.
Redis에는 두가지 배포 방식이 있습니다. 바로 Sentinel과 Cluster입니다. 간단하게 설명해서 Sentinel은 가용성에 초점을 두고 있고 Cluster는 확장성에 초점을 두고 있는 배포 방식입니다.
Redis의 장애 상황에 대처하기 위해선 가용성을 높여주는 Sentinel 방식을 채택하면 됩니다.
Sentinel
Sentinel은 기본적으로 RDBMS에서 높은 가용성을 위해 사용하는 전략인 Replication (리플리케이션 혹은 레플리케이션) 전략을 도와주기 위한 설정 같은 것입니다.
Sentinel을 사용하면 Redis의 높은 가용성을 챙길 수 있게 됩니다.
Sentinel의 역할
Sentinel은 마스터 노드, 레플리카 노드에 대한 모니터링을 진행해주고 Redis를 활용해서 할 수 있는 Pub/Sub 메시징으로 알람도 보내줄 수 있습니다.
또한, 마스터 노드가 죽어버리면 다른 레플리카를 마스터 노드로 승격시키기 위한 투표가 진행됩니다. 이 방식을 의회 방식이라고 합니다.
쉽게 말해서 Sentinel은 마스터 노드의 상태를 계속 확인하고 있다가 죽으면 다른 레플리카를 마스터로 승격시키는 역할을 합니다.
Sentinel 설정하기
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
sentinel monitor resque 192.168.1.3 6380 4
sentinel down-after-milliseconds resque 10000
sentinel failover-timeout resque 180000
sentinel parallel-syncs resque 5
Redis를 설치하면 기본적으로 Sentinel.conf 라는 설정파일이 존재합니다.
안에는 Sentinel을 설정하기 위한 설정 정보들이 들어있습니다. 하나씩 살펴보도록 하죠.
sentinel monitor <master-name> <ip> <port> <quorum>
Sentinel이 모니터링할 마스터 노드를 설정하는 것입니다. Sentinel은 마스터 노드에 장애가 발생했을 때 Sentinel들이 투표해서 레플리카를 마스터로 승격시킨다고 하였습니다. quorum은 그 때 필요한 최소 투표 수입니다.
즉, quorum이 2이면 최소 2개의 Sentinel이 레플리카를 마스터 노드로 승격시키는 것을 동의해야 승격이 된다는 의미입니다.
sentinel down-after-milliseconds <master-name> <time>
Sentinel이 마스터 노드에 <time>만큼 통신이 두절되면 Sentinel이 레플리카를 마스터 노드로 승격시키겠다는 뜻입니다.
sentinel failover-timeout <master-name> <time>
Sentinel이 마스터 노드의 failover에 대한 타임아웃을 설정하는 설정입니다.
sentinel parallel-syncs <master-name> <number>
Sentinel이 마스터노드가 failover후 동기화 할 개수를 정하는 설정입니다.
이제 본격적으로 Sentinel에 대해 알아보도록 하죠.
Sentinel을 배포할 때 주의해야 하는 사항이 몇가지 있는데
- 적어도 세 개의 Sentinel 인스턴스 사용하기
- Sentinel 인스턴스는 독립적인 환경에서 실행하기
- Redis는 높은 성능을 위해 비동기 복제가 이루어지므로 데이터 유실 가능성이 존재
- Sentinel과 Docker, NAT Gateway의 사용시 포트 매핑에 대한 주의 사항 숙지하기
하나씩 알아보도록 하겠습니다.
Sentinel 사용시 주의 사항
1. 적어도 세 개의 Sentinel 인스턴스 사용하기
2. Sentinel 인스턴스는 독립적인 환경에서 실행하기
1번과 2번이 연결되는 내용이라 한번에 보겠습니다.
이번 챕터에서 사용하기 위해 유닉스 아트로 되어있는 그림을 준비해봤습니다. 여기서 등장하는 용어는 총 네개입니다.
- Master : 마스터 노드입니다. 우리는 이 챕터에서 마스터 노드는 M1, M2 이런 식으로 부를겁니다.
- Replica : 레플리카 노드입니다. 우리는 이 챕터에서 레플리카를 R1, R2 이런 식으로 부를겁니다.
- Sentinel : 우리가 생성한 Sentinel입니다. 여기선 S1, S2 이런 식으로 부릅니다.
- Client : 클라이언트는 Redis 서버가 될 수도 있고 우리의 애플리케이션 서버가 될 수도 있습니다. 스프링이라면 스프링을 올려놓은 서버가 되겠네요. 말 그대로 Redis를 사용하는 서버입니다. C1, C2 이런 식으로 부르겠습니다.
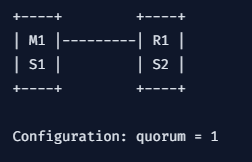
왜 Sentinel 인스턴스가 세 개 이상이어야 하는지 보여드리겠습니다.
우리는 마스터 노드 한개에 레플리카를 하나 두고 있습니다.
만약 마스터 노드가 죽어버리면 어떻게 되나요?

맞습니다. 레플리카가 마스터로 승격됩니다. M1이 죽고 R1이 M1이 되었네요.
이 때 S1과 S2가 투표를 진행해서 레플리카를 승격시켰습니다.
하지만 만약 마스터 노드뿐만 아니라 서버 전체가 다운되면 어떻게 될까요?
그럼 S2 혼자 독단으로 승격을 결정해야합니다. 이는 굉장히 위험한 방식입니다. 대통령 선거도 후보가 한명이면 의미가 없는 것과 같습니다.
때문에 quorum을 1로 설정하는 것은 굉장히 위험합니다.
그래서 quorum을 2로 설정하고 Sentinel을 각각 독립된 인스턴스에 배포해야 합니다.
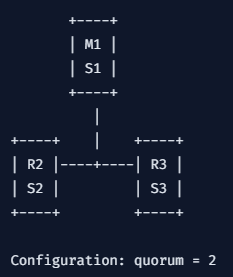
그럼 안전해지겠죠?
이렇게 레플리카에 Sentienl을 배포해도 되지만 Client에 배포해도 괜찮습니다.
예를 들면 이런 그림이 될 수 있겠네요.

3. Redis는 높은 성능을 위해 비동기 복제가 이루어지므로 데이터 유실 가능성이 존재
만약 마스터 노드가 죽어버리면 Redis는 비동기 복제가 이루어지므로 데이터 유실 가능성이 존재합니다.
때문에 Redis에선 쓰기 작업을 기존 마스터 노드에 하지 않고 새롭게 마스터 노드가 된 레플리카에 쓰기 작업을 진행해야합니다.

때문에 우리는 Sentinel 설정파일에 아래와 같은 설정을 추가해줘야합니다.
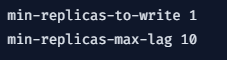
이렇게 설정하면 클라이언트가 마스터 노드에 적어야 하는 쓰기 작업을 승격된 레플리카에 적기 시작합니다. 이렇게 데이터 유실을 완화할 수 있습니다.
만약 서비스가 정말 커서 Redis에 쓰는 작업이 초단위로 몇백개씩 이뤄진다면 데이터 유실을 피할 수는 없을 것입니다.
하지만 Redis는 RDBMS가 아니기 때문에 캐시 데이터 몇개 유실된다고 큰일이 나진 않습니다. 그냥 RDBMS에서 조회해서 다시 Redis에 올리면 되니까요. 사용자는 전혀 눈치채지 못할 것입니다.
그렇다고 유실되는 것을 막지 않으면 계속 죽어있는 마스터 노드에 데이터를 쓰고있을테니 이 부분은 확실히 막긴 막아야겠죠?
4. Sentinel과 Docker, NAT Gateway의사용시 포트 매핑에 대한 주의 사항 숙지하기
이 부분은 조금 내용이 어렵습니다. 하지만 중요하기 때문에 정리해보겠습니다.
만약 Redis를 도커에 올려서 사용하는 경우에 Sentinel을 사용한다면 문제가 발생할 수 있다는 얘기입니다.
보통 요즘 도커 컨테이너에 애플리케이션을 많이 올려 사용하기 때문에 개인적으로는 크리티컬한 문제라고 생각합니다.
Docker의 동작 방식
도커 같은 경우 도커 컨테이너 안에서 실행되는 프로그램들은 각각의 프로그램들이 사용하고 있는 포트들과 대응되는 다른 포트들에 노출되어 있습니다.

이렇게 포트들을 노출시킨다는 말입니다.
이렇게 포트들을 노출시키는 것은 같은 서버, 같은 시간, 같은 포트를 사용하는 여러개의 컨테이너들을 동작시킬 때 유용합니다. 또한, 포트뿐만 아니라 IP 주소를 리매핑하는 전략이라고 볼 수 있습니다.
즉, 노출되어 있는 포트, IP 주소를 다시 매핑시키는 것이 도커의 전략이라고 할 수 있습니다.
예를 들어서
MySQL을 도커로 배포해야한다면 Docker-Compose로 설정파일을 작성할 것입니다.
만약 MySQL을 3330포트로 매핑하고싶다면
0.0.0.0:3330 -> 3306/tcp
이렇게 리매핑을 시킬 것입니다.
도커는 이것을 허용한다는 의미입니다. 실제로 위의 예제처럼 3330 포트로 도커 컨테이너를 띄우면 컨테이너에 외부에서 접근하고 싶은 경우 3330 포트로 접근해야합니다.
도커 내부적으로는 3330 포트로 들어온 네트워크를 3306으로 "리매핑" 시킨다는 것을 이야기한 것입니다.
이런 포트 리매핑 전략은 두 가지 관점에서 Sentinelㅇ르 운영하는 데 문제가 될 수 있습니다.
- Sentinel은 다른 Sentinel이 더이상 동작하지 않는 것을 자동으로 감지하기 위해 각각의 Sentinel들이 연결을 위해 열어두고 있는 포트나 IP 주소에 hello 메시지를 보내면서 통신하고 있기 때문에 문제가 됩니다.
즉, Sentinel들은 마스터 노드의 상태를 확인한다던가 하는 내부적으로 메트릭을 보내기 위해 메시지를 보내면서 통신하고 있다는 얘기입니다.
하지만 포트를 리매핑하게 되면 Sentinel입장에선 전혀 감지할 수가 없습니다. 그러므로 Sentinel끼리 주고받는 메시지 혹은 정보가 올바르지 않게 될 수 있습니다. - 레플리카들은 마스터노드와 비슷한 방식으로 INFO 정보들을 리스트업 해두고 있는데 이 주소들은 멀리 떨어진 (논리적 혹은 물리적으로 분리된) 동료들과 TCP 연결을 체크하는 마스터에 의해 감지됩니다.
이때 TCP 연결을 위해 handshake 과정이 있어야 하는데 만약 포트가 리매핑이 된다면 앞선 1번의 이유 때문에 TCP연결을 할 수 없는 상황이 발생합니다.
이러한 이유로 시스템의 관점에서 어떤 레플리카가 마스터로 승격되기 괜찮은지 모르기 때문에 (포트 리매핑이 되면 마스터고 레플리카고 어떤 상태인지 모르는 상태가 되기 때문에) 마스터 노드의 장애회복을 절대로 할 수 없는 상황이 생깁니다.
그러므로 "1대1로 매핑되는 도커"를 구성하지 않는 이상 도커를 사용하여 배포한 일련의 마스터 노드 혹은 레플리카 노드들은 Sentinel을 사용할 때 필요한 모니터링을 사용할 수 없습니다.
만약 도커를 사용해야 한다면 아래의 설정을 추가해줘야합니다.

이는 Sentinel이 어떤 IP 주소, 포트로 정보를 주고 받을 것인지 각 Sentinel끼리 정해놓는 설정입니다.
잉? NAT Gateway는 왜?
도커는 알겠고 NAT Gateway는 왜 그럴까요?
NAT Gateway 자체가 private하게 관리되는 서버를 public한 통신이 가능하도록 만들어주는 게이트웨이이기 때문입니다.
앞서 설명했던 포트 리매핑은 단순히 포트만 해당하는 것이 아닙니다. IP 주소를 리매핑하는 것도 포함이 됩니다.
NAT Gateway는 내부적으로 private하게 감싸져있는 IP주소를 가지고 있고 만약 외부 네트워크 통신이 필요하다면 이 private한 IP주소를 public하게 바꿔서 매핑시키는 역할을 하기 때문입니다.
이때 앞서 설명했듯이 Sentinel 내부적으로 메시지를 통해 정보를 주고 받는 과정이 IP 주소를 리매핑하는 NAT Gateway 때문에 불가능해진다는 특징이 있습니다.
때문에 NAT Gateway 또한, 도커와 마찬가지로 사용한다면 위의 설정을 추가해줘야합니다.
이외의 방법
Redis의 장애는 일시적이고 많이 발생하지 않기 때문에 가용성을 위해 인스턴스를 많이 만들어 두는 것은 자원 낭비라고 생각할 수 있습니다. 그럴땐 아래와 같은 방법으로 Redis를 운용할 수 있습니다.
- AWS의 Auto-Scaling같이 Redis 인스턴스를 스탠바이 시켜둔다
- AWS의 ElasticCache for Redis 혹은 Azure Cache for Redis 혹은 Google Cloud MemoryStore for Redis와 같이 자동적으로 인스턴스의 크기를 변경할 수 있는 클라우드 기반 캐싱 솔루션을 생각해볼 수 있습니다.
- 모니터링과 알람을 통해 수동적으로 캐시 서버를 관리하는 방법
마치며
장애회복이라는 카테고리로 처음 출범하는 포스팅이었는데 꽤나 의미있는 포스팅이 된 것 같습니다.
이 카테고리는 앞으로 실환경에서 장애상황에 어떻게 대처해야 하는지 이론적인 방법을 알아보기 위해 만들어졌습니다.
앞으로 주된 공부가 되지 않을까 싶네요.
이렇게 Redis를 이용해 가용성을 높이는 방법에 대해서 알아봤습니다. 긴 글 읽어주셔서 감사합니다. 오늘도 즐거운 하루 되세요~
출처
https://redis.io/docs/management/sentinel/#sentinel-docker-nat-and-possible-issues
High availability with Redis Sentinel
High availability for non-clustered Redis
redis.io
https://velog.io/@roycewon/Redis-Sentinel
Redis Sentinel
참고 https://redis.io/docs/management/sentinel/Clustered가 아닌 환경에서 고가용성 제공하기Redis Sentinel은 Redis 클러스터를 사용하지 않는 환경에서 고가용성을 제공하는 기능을 한다.전체적으로, 아래와 같
velog.io
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| @Transactional로 분산 트랜잭션을 구현할 수 있을까? (0) | 2024.03.22 |
|---|---|
| JWT 인증에서 Redis에 장애가 발생했을 때 대비책에 대한 전략 (0) | 2024.01.28 |
| 데이터베이스 동시성 제어 (0) | 2024.01.20 |
| Redis와 Memcached 동시성 문제 (0) | 2024.01.14 |
| 데이터베이스 프로시저 (Database Procedure) (0) | 2024.01.12 |