본 포스팅은 인프런의 정수원님의 스프링 배치 강의를 듣고 정리한 포스팅입니다. 더 자세한 내용은 강의를 참고해주세요.
Chunk
기본 개념
- Chunk 란 여러 개의 아이템을 묶은 하나의 덩어리, 블록을 의미
- 한번에 하나씩 아이템을 입력 받아 Chunk 단위의 덩어리로 만든 후 Chunk 단위로 트랜잭션을 처리함, 즉, Chunk 단위의 Commit 과 Rollback 이 이루어짐
- 일반적으로 대용량 데이터를 한번에 처리하는 것이 아닌 청크 단위로 쪼개어서 더 이상 처리할 데이터가 없을 때까지 반복해서 입출력하는데 사용됨
- Chunk<I> vs Chunk<O>
- Chunk<I>는 ItemReader로 읽은 하나의 아이템을 Chunk 에서 정한 개수만큼 반복해서 저장하는 타입
- Chunk<O>는 ItemReader로부터 전달받은 Chunk<I> 를 참조해서 ItemProcessor에서 적절하게 가공, 필터링 한 다음 ItemWriter 에 전달하는 타입
우선 Chunk에 대해서 간단하게 설명해보도록 하겠습니다.
Chunk는 간단하게 설명해서 트랜잭션 커밋을 이루는 단위입니다.
너무 대충 설명했나요?
트랜잭션은 트랜잭션의 특징(ACID) 중에 A에 해당하는 Atom 즉 원자성을 보장해야 합니다. 예를 들어서 10건의 데이터가 있으면 5건까지는 잘 되다가 6건째부터 갑자기 예외가 터져서 프로그램이 다운됐다. 그럼 5건의 데이터만 완료되고 나머지 5건의 데이터는 완료되지 않은 상황이 벌어집니다. 이건 꽤 큰일이죠
엥 그게 왜? 라고 하신다면 아직 트랜잭션에 대해 감이 없으신것입니다.
예를 들어서 10명의 사원에게 월급을 보내는 로직이라고 가정해봅시다. 자 사원 1부터 순서대로 10까지 300만원의 월급이 들어갑니다. 근데 5명의 월급은 정상적으로 들어갔는데 6번째에서 예외가 터져서 나머지 5명은 월급이 안들어갔습니다. 이때 우리는 어떻게 해야할까요?
1. 월급을 처음부터 다시 준다.
이 방법은 잘못됐습니다. 그렇게 되면 처음 받았던 5명은 월급을 또 받게 되니까요.
2. 못준 사람에게 월급을 준다.
이 방법도 좋은 방법은 아닐겁니다. 프로그램이 용빼는 재주가 있는 것도 아니고 받았는지 안받았는지 어떤 수로 알까요?
3. 월급 줬던 사람것을 다시 돌려받고 처음부터 다시 준다.
이 방법이 가장 현실적인 방법일 것입니다.
따라서 트랜잭션은 위의 세가지 방법 중에서 3번을 채택하고 있습니다.
자 이제 우리는 트랜잭션의 원자성에 대해서 간단하게 알아봤습니다. 그럼 Chunk가 트랜잭션의 원자성을 보장하기 위한 단위라는 것도 아시겠죠.
하지만 Chunk는 단순히 원자성을 보장해주는 정도의 수준이 아닙니다. Chunk의 매력에 대해서 좀 더 설명해보겠습니다. 그리고 이 매력을 알게 되면 왜 스프링 배치가 대용량 데이터를 관리하는데에 특화됐다고 하는지 아실겁니다.
자 위의 예제는 큰 문제가 있습니다. 만약 10건이 아니라 100만건이라면 어떨까요? 100만건이라면 두가지 문제가 있습니다.
1. 100만건을 모두 메모리에 올린다
JVM이 버텨줄지 모르겠네요...
2. 중간에 끊기는 경우
100만건을 다 메모리에 올렸다고 가정해봅시다. 50만건까지는 잘 이행됐습니다. 하지만 50만1번째에서 예외가 터졌습니다. 그럼 50만건의 성공을 전부 롤백하고 다시 처음부터 시작해야합니다. 이는 다시 1번 문제로 돌아갑니다.
때문에 우리는 Chunk를 이용해서 100만건이라면 Chunk사이즈를 1만건으로 잡아두고 50만건이 쭉쭉 성공하고 51만번째에서 예외가 터졌다면 Chunk사이즈인 1만건에 대해서만 롤백을 하면 됩니다. 이는 더 효율적이죠
Chunk에 대해 조금 이해가 되셨나요?
이제 청크 프로세스에서 프로그래밍적으로 한번 접근해보도록 하겠습니다.
먼저 Source에서 ItemReader를 이용해 Item을 Chunk<I>에 하나씩 쌓습니다. 이때 Soucre는 파일이 될 수도 있고, 데이터베이스가 될 수도 있고, json이 될 수도 있습니다.
Chunk<I>는 내부적으로 가져온 데이터를 List로 저장해 관리합니다. 이 List로 관리되고 있는 데이터들이 Chunk Size에 도달했는지 확인합니다. 도달하지 못했다면 다시 ItemReader로 돌아가 데이터를 하나씩 List에 쌓습니다.
Chunk Size에 도달했다면 List에 있는 데이터를 모아서 ItemProcessor에 넘겨줍니다. ItemProcessor에서는 Iterator로 하나씩 넘겨가며 데이터를 가공합니다.
최종적으로 가공된 Item들은 Chunk<O>에 담아서 내부적으로 List로 정리해서 ItemWriter에게 넘겨줍니다. ItemWriter는 정리된 List를 DB에 저장합니다.
이를 그림으로 표현하면 다음과 같습니다.

이 때 ItemReader와 ItemProcessor는 하나씩 수행되고 ItemWriter에서 Chunk 단위로 일괄 처리됩니다.
ChunkOrientedTasklet
기본 개념
- ChunkOrientedTasklet은 스프링 배치에서 제공하는 Tasklet의 구현체로서 Chunk 지향 프로세싱을 담당하는 도메인 객체
- ItemReader, ItemProcessor, ItemWriter를 사용해 Chunk 기반의 데이터 입출력 처리를 담당한다.
- TaskletStep에 의해서 반복적으로 실행되며 ChunkOrientedTasklet이 실행 될 때마다 매번 새로운 트랜잭션이 생성되어 처리가 이루어진다.
- Exception이 발생할 경우, 해당 Chunk는 롤백 되며 이전에 커밋한 Chunk는 완료된 상태가 유지된다.
- 내부적으로 ITemReader를 핸들링하는 ChunkProvider와 ItemProcessor, ItemWriter를 핸들링하는 ChunkProcessor 타입의 구현체를 가진다.
이러한 구조를 그림으로 보면 이런 형태입니다.

TaskletStep에서부터 ChunkProvider, ChunkProcessor로 이어지는 순서도를 확인하면 다음과 같습니다.

1. 우선 TaskletStep이 ChunkOrientedTasklet으로 execute() 명령을 내립니다.
2. 그 다음 ChunkOrientedTasklet은 ChunkProvider에게 데이터를 읽을 것을 명령합니다 (provide()). 그럼 Chunk Size만큼 반복하면서 데이터를 읽고 Chunk<I>에 저장합니다.
3. Chunk Size 만큼 저장했으면 ChunkOrientedTasklet은 ChunkProcessor에 process(inputs) 명령을 내립니다. 여기서 inputs은 Chunk<I>에 저장된 데이터들입니다.
4. ChunkProcessor는 ItemProcessor를 이용해 Chunk Size만큼 반복하면서 데이터를 가공합니다.
5. 그리고 마지막으로 ChunkProcessor는 ItemWriter에게 데이터 저장을 명령으로 끝이납니다.
이게 한 사이클이고 ChunkOrientedTasklet은 다시 처음으로 돌아와 읽을 데이터가 없을 때까지 해당 사이클을 계속 반복합니다.
ChunkProvider
기본 개념
- ItemReader를 사용해서 소스로부터 아이템을 Chunk Size 만큼 읽어서 Chunk 단위로 만들어 제공하는 도메인 객체
- Chunk<I>를 만들고 내부적으로 반복문을 사용해서 ItemReader.read()를 계속 호출하면서 Item을 Chunk에 쌓는다.
- 외부로부터 ChunkProvider가 호출될 때마다 항상 새로운 Chunk가 생성된다.
- 반복문 종료 시점
- Chunk Size만큼 Item을 읽으면 반복문이 종료되고 ChunkProcessor로 넘어감
- ItemReader가 읽은 Item이 null일 경우 반복문 종료 및 해당 Step 반복문까지 종료
- 기본 구현체로서 SimpleChunkProvider와 FaultTolerantChunkProvider가 있다.
구조를 보면 다음과 같이 확인할 수 있다.

ChunkProvider의 내부 메서드 중 하나인 provide()를 확인해보도록 하겠습니다.

우선 Item을 담을 Chunk<I>를 생성합니다. 그리고 provide() 메소드 호출마다 새롭게 생성됩니다. 그리고 Chunk Size만큼 반복문을 실행하면서 read()를 호출합니다.
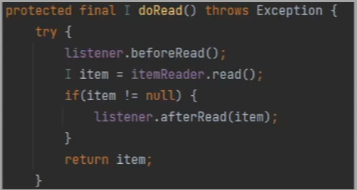
그 후 ItemReader가 Item을 한개 씩 읽어서 리턴합니다.
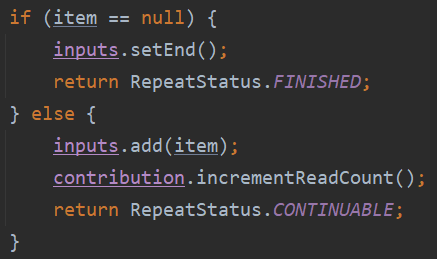
더 이상 읽을 Item이 없는 null 일 경우 반복문 종료 및 전체 Chunk 프로세스를 종료합니다.
이렇게 ChunkProvider가 할 일을 마칩니다.
ChunkProcessor
기본 개념
- ItemProcessor를 사용해서 Item을 변형, 가공, 필터링하고 ItemWriter를 사용해서 Chunk 데이터를 저장, 출력한다.
- Chunk<O>를 만들고 앞에서 넘어온 Chunk<I>의 Item을 한 건씩 처리한 후 Chunk<O>에 저장한다.
- 외부로부터 ChunkProcessor가 호출될 때마다 항상 새로운 Chunk가 생성된다.
- ItemProcessor는 설정 시 선택사항으로서 만약 객체가 존재하지 않을 경우 ItemReader에서 읽은 Item그대로가 Chunk<O>에 저장된다.
- ItemProcessor 처리가 완료되면 Chunk<O>에 있는 List<Item>을 ItemWriter에게 전달한다.
- ItemWriter 처리가 완료되면 Chunk 트랜잭션이 종료하게 되고 Step 반복문에서 ChunkOrientedTasklet이 새롭게 생성된다.
- ItemWriter는 Chunk Size 만큼 데이터를 Commit 처리하기 때문에 Chunk Size는 곧 Commit Interval (커밋 주기) 이 된다.
- 기본 구현체로서 SimpleChunkProcess or와 FaultTolerantChunkProcessor가 있다.
ChunkProcessor 의 구조를 확인하면 다음과 같습니다.
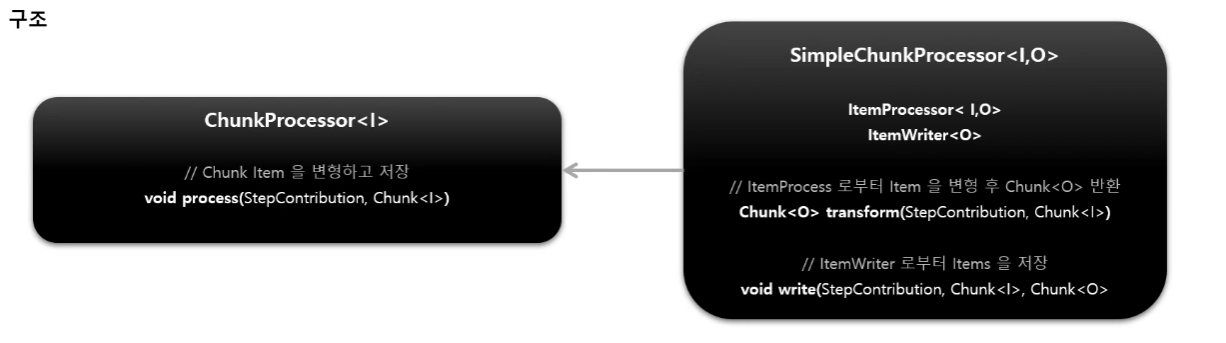
ChunkProcessor 의 process 메서드를 한번 확인해보겠습니다.
1. ChunkProvider에서 받은 Chunk<I>를 가지고 아이템 가공 및 저장을 Chunk<O>를 생성합니다.
2. 읽은 아이템 개수만큼 반복하면서 doProcess()를 호출합니다. 이때 ItemProcessor가 없다면 Item을 그대로 반환하고 ItemProcessor가 있다면 process로 가공 후 반환합니다.
3. ItemProcessor로 필터링 된 아이템 개수를 저장하고
4. 가공 처리된 Chunk<O>의 List<Item>을 ItemWriter에게 전달합니다.
5. 마찬가지로 ItemWriter가 없으면 그대로 반환하고 있다면 write메서드를 이용해 Item들을 일괄 처리합니다.
여기까지 Chunk 지향처리 그중에서도 Chunk, ChunkProvider, ChunkProcessor에 대해서 알아봤는데요. 다음 포스팅에선 ItemReader, ItemProcessor, ItemWriter에 대해 자세히 알아보는 시간을 가져보도록 하겠습니다.
'Spring > Spring Batch' 카테고리의 다른 글
| Chunk 지향 처리 : ItemReader, ItemProcessor, ItemWriter 개요 (0) | 2022.10.04 |
|---|---|
| 스프링 배치 키워드 정리 (0) | 2022.10.03 |
| 스프링 배치 @JobScope, @StepScope (0) | 2022.09.29 |
| 스프링 배치 도메인 이해 : JobRepository, JobLauncher (0) | 2022.09.24 |
| 스프링 배치 도메인 이해 : ExecutionContext (0) | 2022.09.23 |