다음 프로젝트를 기획하면서 Redis를 사용해봐야겠다는 생각을 하게 되었습니다. 기존 이론적으로 알고 있었던 내용으로는 Redis가 캐싱이나 세션 데이터 저장소로서 사용된다는 것은 알고 있었지만 실제 어떻게 사용하는지 그 이외의 사용처는 무엇이 있는지에 대해서 공부가 부족해 조금 알아보게 되었습니다.
이번 공부는 특별히 요즘 핫한 Open AI의 Chat GPT 3.5 버전을 이용해 공부를 진행했습니다. 하지만 어디까지나 생성형 대화 AI인만큼 정보가 정확한지에대한 더블체크를 진행했으니 정보의 신뢰성은 걱정하지 않으셔도 될 것 같습니다. 때문에 이번 포스팅의 출처에는 제가 정보를 얻은 출처가 아닌 더블체크에 사용된 출처가 기입될 예정이니 참고해주시면 감사하겠습니다.
또한, GPT를 이용해 얻은 정보들은 GPT를 이용해 얻었다고 표시를 해두겠습니다. 서론이 길었네요 바로 출발해보도록 하겠습니다.
NoSQL
NoSQL에 대한 소개를 잠시 진행하고 넘어가보도록하죠.
NoSQL은 2009년에 등장한 데이터베이스로 기존 RDBMS의 한계를 타파하고자 개발된 데이터베이스입니다. RDBMS에서는 저장할 수 없었던 비정형데이터를 저장할 수 있고, 느슨한 데이터 스키마를 가지고 있어서 수평적인 확장에 용이하고 유연한 특징을 가지고 있습니다.
후에 블로그 포스팅으로 정리할 수도 있지만 NoSQL은 보안적으로는 상당히 메롱한 부분이 있는데요. 때문에 NoSQL은 높은 데이터 정합성이나 높은 신뢰성을 요구하는 서비스에는 부적절한 데이터베이스로 알려져있습니다.
하지만 비정형 데이터를 저장해야하거나, 데이터의 총량이 매우 큰 경우에는 NoSQL을 선택하는 것이 나쁘지 않은 선택이 될 수 있습니다.
그럼 Redis에 대해서 본격적으로 알아보도록 하죠
Redis
우리가 이번에 알아볼 Redis는 NoSQL중에서 Key-Value Store로 잘 알려진 데이터베이스입니다. Key-Value Store는 말 그대로 Key와 Value 단 두가지 형태만을 가지고 데이터를 저장하는 방식입니다.
Redis는 다른 NoSQL 데이터베이스 중에서도 가장 뛰어난 성능을 보여줍니다. Redis가 성능을 극단적으로 향상시킬 수 있었던 이유에는 여러가지 이유가 있습니다. 그 이유에 대해서 한번 알아보죠
Redis의 성능향상 비결 (GPT 사용)
- Redis는 주로 in-memory 데이터 스토리지를 이용합니다. 이 말은 RAM을 사용한다는 말이고 RAM은 데이터 읽기 속도가 매우 빠른 것으로 알려져있죠. 이 RAM을 이용해 데이터를 읽고 쓰기 때문에 성능이 뛰어날 수 있었던 것입니다.
- Redis는 높은 성능을 이끌어낼 수 있는 여러개의 자료구조를 지원합니다. 예를 들어서 Sorted Set과 같은 자료구조는 가장 위에있거나 가장 아래있는 데이터를 빠르게 가져올 수 있도록 유도할 수 있습니다.
- Redis는 싱글 스레드 아키텍처를 사용했기 때문에 스레드 동기화와 Context Switching과 같은 오버헤드를 피할 수 있었습니다. 이러한 결과로 더 빠르고 더 효율적인 데이터를 처리하고 반환받을 수 있게 되었습니다.
- Redis는 경량화된 프로토콜을 가지고 네트워크 최적화를 진행했는데 이는 비동기 I/O를 지원한다는 의미입니다. 이러한 방식으로 Redis가 많은 수의 연결을 핸들링할 수 있게 해주었고 요청을 최소한의 레이턴시로 처리할 수 있게 되었습니다.
- Redis는 비동기 실행을 지원합니다. 예를 들어서 non-blocking I/O나 Pub/Sub 메세징이 바로 그것이죠. 이러한 실행들은 Redis가 최소한의 blocking과 waiting을 가지고 큰 볼륨의 요청이나 데이터를 핸들링할 수 있게 해줬습니다.
- 뒤에 설명할 Redis의 배포방식 중 하나인 Cluster 방식을 지원하기 때문에 여러개의 Redis 인스턴스를 늘려서 DB부하를 줄이고 병목현상을 최소화시켰습니다.
이런 다양한 방법으로 Redis는 NoSQL중에서도 파격적으로 성능을 이끌어낼 수 있었습니다. 이제 Redis가 지원하는 자료구조에 대해서 알아보도록 하죠.
Redis의 자료구조 (GPT 사용 후 더블체크)
1. String
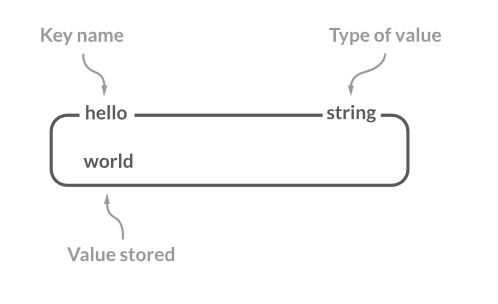
첫 번째로 String입니다. String은 가장 기본이 되는 단순한 String value로 저장하는 간단한 key-value 쌍으로 저장합니다. String은 다양한 목적에서 사용되는데 예를 들면 세션 데이터를 저장하거나, 시스템의 성능을 올리거나, 애플리케이션 세팅을 할 때 사용합니다.
2. Set
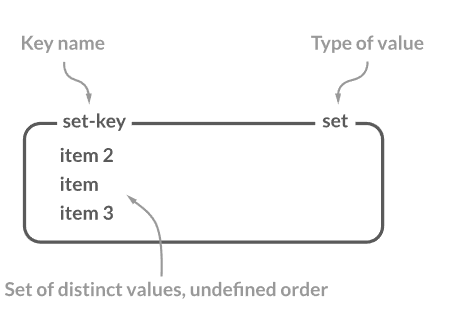
Set은 순서없는 String을 모아둔 컬렉션입니다. Set은 태그나 프로덕트 카테고리등과 같은 유니크한 값을 저장하기위해 사용됩니다. 해당 타입은 속도가 정말 빠르지만 순서가 없습니다.
3. Sorted Set
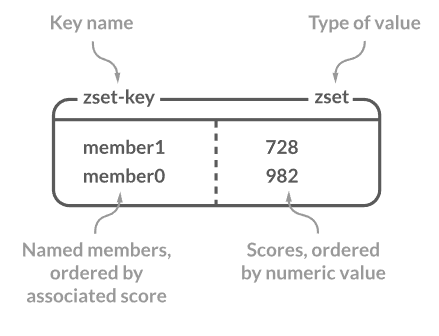
Sorted Set은 Set과 비슷합니다. 하지만 각각의 요소들은 정렬된 상태로 List에 담기고 Sorted Set은 객체들을 정렬해야하는 리더보드나 time-series data와 같은 데이터를 저장할 때 사용됩니다.
4. List
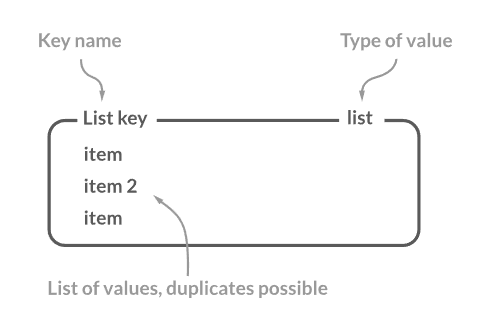
List는 String 값을 모아둔 컬렉션입니다. List는 Queue나 Stack 혹은 유저 액션이나 애플리케이션 이벤트같은 time-series를 저장할 때 사용합니다. range메서드를 활용해 범위로 값을 가져올 수 있기 때문에 값이 아무리 커져도 실행 시간이 크게 차이나지 않는 괴물같은 성능을 보여줍니다.
5. Hash

Hash는 field-value 쌍으로 값을 저장하는 컬렉션입니다. key는 String이고 value는 String, number 혹은 다른 타입의 데이터가 저장될 수 있습니다. Hash는 유저 프로필같은 복잡한 객체를 저장할 때 용이합니다. 그리고 특정한 필드에 대한 효율적인 lookup이나 업데이트와 같은 곳에서도 사용됩니다. 메모리를 적게 차지하기 때문에 수백만개의 오브젝트를 넣을 수 있어서 엄청난 효율성을 가집니다.
이렇게 Redis의 자료구조에 대해서 알아봤습니다. Redis는 Key-Value를 저장할 수 있기 때문에 단순히 String만 저장하는 줄 알았는데 다양한 자료구조를 지원했습니다.
이러한 자료구조를 지원한다는 특징은 같은 Key-Value Store 인 Memcached 데이터베이스와 차별화되는 부분입니다. 이런 다양한 자료구조를 바탕으로 더 다양한 데이터를 저장할 수 있죠.
각각의 Redis 자료구조들은 데이터의 접근에 대한 높은 성능이나 가공을 위한 최적화가 되어있는 특별한 기능을 제공합니다. 예를 들어 List는 특정한 위치에 요소를 삽입하고 붙이고 popping하는 기능을 제공하는 반면에 Set은 추가하고 제거하고 유니크한 객체들을 querying하는 기능을 제공하죠.
전체적으로 Redis의 자료구조들은 효율적이고 유연한 방법으로 in-memory 데이터를 가공하고 저장하는 다양한 방법들을 제공하기위해 설계되었습니다.
Redis의 사용처 (GPT 사용 후 더블체크)
Redis의 사용처는 크게 캐싱, 세션 스토리지, Pub/Sub Messaging, Queue, 실시간 분석 등이 있습니다. 하나씩 알아보도록 하죠.
1. Cache
Redis는 메모리에서 데이터를 자주 꺼내야 하는 상황에서 쓰입니다. 예를 들면 세션 데이터나, 유저 선호도같은 상황에서 주로 사용됩니다.
Redis에 데이터를 저장함으로써 우리는 데이터베이스와 같은 데이터 스토리지에 저장하는 것보다 더 빠른 데이터 접근이 필요한 애플리케이션의 시간을 줄여줍니다.
결과적으로 응답 시간을 줄여주고 더 나은 성능을 보여줄 수 있죠.
2. Session Storage
Redis는 웹 애플리케이션에서 세션 데이터를 저장하는데 사용됩니다. Redis에 세션데이터를 저장함으로써 우리는 여러 서버나 여러 인스턴스를 통해 세션의 상태를 유지할 수 있습니다.
Redis에 세션 데이터를 저장하면 데이터의 확장성과 신뢰성을 유지할 수 있죠.
3. Pub/Sub Messaging
Redis는 애플리케이션 혹은 서비스 사이에 실시간 커뮤니케이션을 용이하게 메시지 브로커로서 역할을 충실히 잘 해냅니다.
Redis는 publish/subscribe 메시지 패러다임을 구현할 수 있는데 메시지 패러다임에서 메시지는 하나 혹은 그 이상의 채널에 보내지고 메시지를 받는 쪽인 subscribe에서 채널을 통해 메시지를 받을 수 있습니다.
Pub/Sub Messaging을 구현하기 위한 Overview를 소개해드리자면
- 대화를 구성하는 데이터들은 Set 자료구조에 저장한다.
- 최근 10개의 메시지는 List에 저장한다.
- 유저들의 기본적인 정보는 Hash에 저장한다.
- 최근 대화는 Sorted Set에 저장한다.
이렇게 구현할 수 있겠습니다.
4. Event Queue
Redis는 job queue나 task queue를 구현하기위해도 사용됩니다. queuing에 Redis를 이용함으로써 우리는 백그라운드에서 작동하거나 임계영역에서 작동하는 우리의 애플리케이션으로부터 시간이 절약되는 경험을 할 수 있습니다.
Event에 해당하는 유저의 클릭이나, 유저의 키보드 입력, 유저의 터치 등을 Redis에 저장하고 이를 알맞게 데이터를 처리할 수 있습니다.
Event Queue는 자바스크립트로 array를 이용해 구현이 가능합니다. 하지만 그럼에도 우리가 Redis를 이용해 Event Queue를 구현해야 하는이유는 다음과 같습니다.
- 확장성 : Redis는 많은 수의 동시다발적인 연결을 효율적으로 핸들링할 수 있도록 설계되었습니다. 높은 확장성을 요구하는 애플리케이션에서 좋은 선택이 될 수 있습니다.
- 지속성 : Redis는 데이터 지속성을 지원합니다. 이 말은 이벤트들이 설령 서버가 다시 실행될지라도 저장된 데이터를 다시 가져오는 것이 가능하다는 의미입니다.
- 향상된 기능 : Redis는 이벤트를 관리하는데 다양한 향상된 기능을 제공합니다. 예를 들어 pub/sub 메시징같은 것이 바로 그러한데, 이러한 기능들은 대화에 참여한 다수의 클라이언트들을 실시간으로 관리할 수 있다는 의미입니다.
- 통합 : Redis는 우리의 애플리케이션 스택의 다른 컴포넌트들을 쉽게 통합할 수 있습니다. 예를 들어서 웹 서버나 메시지 브로커같은 기능을 이용해 이를 구현할 수 있습니다.
- 성능 : Redis는 높은 성능을 보여주는데 이러한 성능들은 큰 볼륨의 이벤트들을 적은 레이턴시를 가지고 이상적으로 핸들링할 수 있도록 도와줍니다.
Event Queue와 Message Queue를 헷갈릴 수 있습니다. (제가 헷갈렸거든요..)
Event Queue는 앞서 설명한 것 처럼 유저의 특정 이벤트를 저장하고 관리하는데 초점을 맞춥니다. 하지만 Message Queue는 서로 다른 애플리케이션 사이에 메시지를 주고받으며 통신하는 것을 말합니다.
쉽게 설명해서 Message Queue는 MicroService Architecture에서 서로 다른 도메인끼리 통신을 할 때 사용하는 것이라고 생각하면 쉽습니다.
결제 도메인과 정산 도메인은 서로 컨테이너의 형태로 떨어져있죠. 이 둘이 통신하기 위해서 사용하는 것이 바로 Message Qeuuing System입니다. Message Queuing에는 Apache 의 Kafka나, RabbitMQ, AWS의 SQS 등이 있습니다.
제가 추후에 취직하고 나서 공부해보고 싶은 내용 중 하나이죠.
5. 실시간 분석
마지막으로 Redis를 이용한 실시간 분석입니다. Redis는 실시간 분석 데이터를 저장하는데 사용되기도 하는데요. 예를 들어 이벤트 데이터나 유저의 행동 패턴을 분석한 데이터들이 저장될 수 있는데 Redis에 데이터를 저장함으로써 우리는 실시간 분석 혹은 실시간 데이터 프로세싱을 수행할 수 있습니다.
Redis 배포
사실 여기까지는 잘 몰라도 될 것같아서 조금만 준비했습니다.
Redis를 배포하는 방식에는 Sentinel 과 Cluster 이렇게 두가지 방식이 있습니다. 이것을 구현하고 알아야 할 것이 원래 많아보이는데 지금 공부할 단계는 아니라고 판단해 선택과 집중을 했습니다.
Sentinel : Sentinel은 알람 기능, 마스터 조회, 자동으로 장애에 대해 failover (장애가 발생했을 때 자동으로 시스템이 내려가는 것), 다수결로 투표하여 마스터 노드를 선출하는 것을 제공합니다.
즉 Sentinel은 높은 가용성과 failover같은 Redis의 추가적인 기능을 제공하는 분산시스템입니다.
Cluster : Cluster는 Sentinel과 비슷하지만 다른 점은 sharding 기능이 있다는 것입니다. sharding을 통해 추가적으로 1000개의 노드를 선형적으로 더 생성할 수 있기 때문에 확장성면에서는 Cluster가 조금 더 우위에 있는 모습을 보여줍니다.
마치며
여기까지 Redis에 대한 전체적인 개념에 대해 알아봤습니다. 아무래도 기존 RDBMS는 데이터의 저장만 단순히 수행할 수 있었다면 Redis같은 NoSQL은 조금 더 다양한 분야에서 활용될 수 있다는 것을 알게되는 공부였습니다.
여러분도 기회가 된다면 Chat GPT로 공부해보시면 좋을 것 같습니다. 추가적으로 이번에 보안쪽 인증/인가에 대해서도 GPT로 공부했는데 정말 좋은 공부가 됐습니다. 추후에 이 내용도 블로그에 포스팅할 예정입니다.
참고로 Chat GPT를 사용하신다면 영어로 질답을 하시는 것이 좋습니다. 영어를 읽고 쓰는 것이 조금 부족하시다면 번역기를 사용해서라도 영어로 사용하시는게 조금 더 높은 정확성과 높은 퀄리티를 보장할 수 있습니다.
긴 글 읽어주셔서 감사합니다. 오늘도 즐거운 하루 보내세요!
더블체크 출처
https://redis.com/redis-enterprise/data-structures/
Data Structures | Redis
Designed with developers in mind and unlike simplistic key-value data stores, Redis data structures deliver flexible ways to model your data for many use cases in modern applications.
redis.com
https://severalnines.com/blog/introduction-redis-what-it-what-are-use-cases-etc/
Introduction to Redis (What it is, what are the use cases etc) | Severalnines
Redis has been in existence for more than 12 years. It has been applied in a wide array of applications, and its use cases have been well tested for where it is ample and sufficient to amplify the requirements of the applications. From web solutions, analy
severalnines.com
https://redis.com/glossary/event-queue/
Event Queue | Redis
Learn about event queues, a data structure used in computer programming to manage and process events in an asynchronous, non-blocking way.
redis.com
https://www.baeldung.com/redis-sentinel-vs-clustering
=> Sentinel 과 Cluster의 차이에 대한 Docs
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| Redis를 이용해 세션 구현하기 (with Spring) (0) | 2023.05.03 |
|---|---|
| Redis를 이용해 캐싱 구현하기 (with Spring) (0) | 2023.05.03 |
| 데이터베이스 인덱싱 (B- tree, B+ tree) (0) | 2023.04.21 |
| NoSQL의 BASE속성으로 인한 단점은 단점이 아니다 (0) | 2023.03.22 |
| Elasticsearch (0) | 2023.03.17 |