1. 기존 검색 방식
- LIKE 연산자를 이용한 검색을 했습니다.
2. 기존 검색의 문제점
- 인덱스 설정을 할 수 없습니다.
- 인덱스를 설정하면 시간 복잡도가 O(log n)이지만 인덱스를 설정하지 못하기 때문에 시간 복잡도가 O(n)에 바인딩 즉, 풀스캔으로 조회합니다.
3. ver.2에서 개선한 점
- Elasticsearch의 역색인을 이용해 검색 성능을 20배 (100만행 기준) 끌어올렸습니다.
Elasticsearch
고난
항상 느끼는 것이지만 NoSQL은 진입장벽이 어마어마한 것 같습니다. RDBMS에 너무 익숙해진 것도 있겠지만 하나부터 열까지 새롭지 아니한게 없었습니다.
RESTful API로 테이블 (인덱스)를 만들고 모든 CRUD 또한 RESTful API를 따르고 있었습니다. 또한, GUI도 굉장히 낯설었고 데이터를 어떻게 봐야하는지도 몰랐습니다.
오히려 스프링에서 Elasticsearch를 사용하는 것은 그렇게 난이도 있지 않았지만 다른 부차적인 것들이 저를 괴롭혔습니다.
데이터 마이그레이션
제가 기존에 사용하고 있던 데이터 셋은 약 200개정도 되는 데이터 셋이었습니다. 이것을 검색하기 위해서는 MySQL에 있는 데이터를 Elasticsearch로 마이그레이션 해야 하는 상황이 발생했습니다.
마이그레이션을 하는 방법에는
- 일일이 집어넣기
- Logstash 사용하기
- go-mysql-elasticsearch 사용하기
이렇게 세 가지 였습니다.
사실 200개정도 밖에 안되는 데이터셋이기 때문에 일일이 집어넣는 것도 무리는 아니었습니다. 하지만 제 컨셉상 1000만명의 이용자 수가 있다면 데이터셋이 어마어마하게 클 것이기 때문에 1번은 이행할 수 없었습니다.
남은 두 가지 방법들은 각자 장단점이 있었습니다.
Logstash같은 경우는 SQL문으로 내가 원하는 데이터를 뽑아서 마이그레이션을 할 수 있다는 것과 그렇기 때문에 진입장벽이 상대적으로 낮다는 것이었고, 무엇보다 ELK 스택 덕분에 Elasticsearch와 호환도 잘 된다는 것이 장점이었습니다.
하지만 메모리를 많이 잡아먹고 그렇기 때문에 속도가 느리다는 것이 단점으로 꼽혔습니다.
go-mysql-elasticsearch는 Logstash와 장단점이 반대로 뒤집으면 되기 때문에 고민을 했습니다.
저는 여기서 SQL문을 이용해 데이터를 뽑아낼 수 있다는 사실이 굉장한 메리트로 받아들였습니다.
때문에 저는 Logstash를 이용해 데이터 마이그레이션을 진행했습니다.
JPA와 성능비교
저는 Elasticsearch가 검색에 최적화된 엔진이라고 하길래 성능이 압도적으로 JPA보다 좋을 것이라고 생각했습니다만, 실제로 1000번의 조회를 진행해본 결과
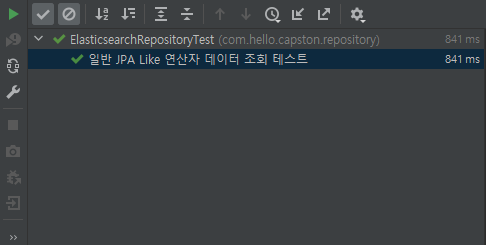
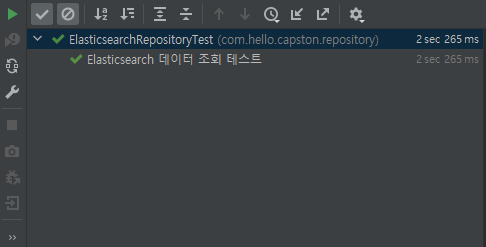
단순 결과만 보고 믿을 수 없었습니다. 많은 엔터프라이즈에서 Elasticsearch를 채택했을 것인데 왜 이런 결과가 나올까?
이 답은 Chat GPT가 알려줬습니다.
- Caching : JPA는 캐싱 매커니즘을 사용했을 것이기 때문에 (1차 캐시) 만약 테스트에서 같은 쿼리를 빠르게 재시작 했을 경우에 데이터베이스는 캐시된 데이터 셋들을 리턴할 수 있을 것이고 그럼 연산이 매우 빨라진다는 것이었죠.
- Overhead of HTTP communication : Elasticsearch는 HTTP에서 작동합니다. 그리고 그것은 JPA와 같이 로컬 SQL을 실행하는 것과 다르게 약간의 오버헤드가 가미될 수 있습니다. 이러한 오버헤드는 특히 루프를 통해 많은 수의 요청을 실행했을 때 더 부각되어 보입니다.
- Setup Time : Elasticsearch는 다수의 필드와 document를 통한 복잡하고 큰 스케일의 텍스트 검색 실행을 위해 설계되었습니다. 이것은 큰 데이터 셋이나 복잡한 검색 연산을 위해 최적화 되어있습니다. 때문에, 작은 텍스트 검색으로도 굉장히 많은 자원이 필요로 합니다. 하지만 LIKE 연산자는 비교적 간단한 연산이기 떄문에 데이터베이스 엔진은 빠르게 실행될 수 있던 것입니다.
- Size of the dataset : 만약 데이터셋이 작다면 Elasitcsearch의 역색인과 분산된 검색의 이점은 뚜렷하지 않을 것입니다. 몇몇 케이스에서 전통적인 RDBMS가 작은 데이터 셋에선 더 빠를수도 있습니다.
이 결과를 보고 그나마 Elasticsearch를 적용하는 것이 더 나은 선택이라는 것을 알 수 있었습니다.
2023-05-27 Update
Chat GPT의 말대로 데이터 셋이 작기 때문에 어쩔 수 없이 성능 차이를 보기 위해선 반복문을 돌려서 테스트를 하는 수밖에 없었습니다.
때문에 데이터 셋을 크게 늘리기로 결정했고 데이터 셋은 100만행으로 늘렸습니다.
그리고 제일 마지막에 있는 Primary Key 기준 테스팅한 결과입니다.


스프링 구동시간을 빼서 진짜 조회하는 시간만 구해봤습니다.

결론
JPA LIKE 연산자를 사용해 100만번째 데이터 검색하는 데 걸린 시간 : 0.434 초
Elasticsearch 를 사용해 100만번째 데이터 검색하는 데 걸린 시간 : 0.021 초
이를 수치로 환산해보면 약 20배의 성능 향상이 있다는 것을 알 수 있었습니다.
이 프로젝트를 통해 얻은 것
- 많은 데이터 셋일 때 검색 성능의 향상
- 데이터 마이그레이션 경험
- MSA로 넘어가기 위한 준비 단계
'사이드 프로젝트 > 온라인 쇼핑몰 ver.2' 카테고리의 다른 글
| 온라인 쇼핑몰 ver.2 (4) : 동시성 문제 해결하기 (0) | 2023.05.21 |
|---|---|
| 온라인 쇼핑몰 ver.2 (3) : JWT 토큰으로 인증 레이어 추가하기 (0) | 2023.05.19 |
| 온라인 쇼핑몰 ver.2 (2) : SMTP 비동기 통신으로 바꾸기 (0) | 2023.05.16 |
| 온라인 쇼핑몰 ver.2 (1) : Redis를 이용해 Session 과 Caching 적용하기 (0) | 2023.05.15 |
| 온라인 홈쇼핑 ver.2 (개요) (0) | 2023.05.14 |