요즘 사이드프로젝트가 끝나고 어떤 공부를 해야할지 고민중이었는데 평소에 궁금했던 gRPC에 대해서 공부해보았습니다. 이번 포스팅에선 서버간 통신에서 REST API의 대안이 된 gRPC에 대해서 정리해봤습니다.
gRPC의 세가지 무기
gRPC는 세개의 무기를 가지고 있습니다. 바로 헤더 압축, Protobuf, 멀티플렉싱이죠. 각각의 특징이 gRPC가 왜 서버간 동기 통신에서 선택받았는지 자세히 정리해보겠습니다.
헤더 압축
저도 gRPC를 공부하면서 깜짝 놀랐습니다. 헤더 압축? 헤더가 뭐 얼마나 된다고 헤더를 압축해?
근데 엄청나게 차이가 많이납니다. 이번 섹션에선 기존 HTTP/1.1을 사용하는 REST API와 HTTP/2를 사용하는 gRPC에 각각 요청을 직접 날려보면서 패킷을 뜯어보고 헤더 압축의 차이가 얼마나 큰지 알아보려고합니다.
우선 준비물이 있습니다.
- python3, pip
- go
- JWT 토큰
- wireshark
하나하나 진행해보겠습니다.
우선 필요한 언어들을 쭉 깔아줍니다. 저는 맥으로 실습했기에 맥 명령어를 정리해봤습니다.
brew install python3
brew install go
python3 -m pip install PyJWT
이렇게 세개를 설치하면 우선 준비 끝입니다.
그리고 파이썬 파일을 하나 만듭니다.
import jwt
import datetime
# 시크릿 키
secret = "my-secret-key"
# 페이로드
payload = {
"sub": "kyoungsuk",
"role": "admin",
"iat": datetime.datetime.utcnow(),
"exp": datetime.datetime.utcnow() + datetime.timedelta(minutes=5)
}
# JWT 생성
token = jwt.encode(payload, secret, algorithm="HS256")
print(token)
그리고 python3로 이 파일을 실행하면 JWT토큰이 튀어나옵니다.
python3 generate_jwt.py
저는 generate_jwt.py로 이름을 지었고 이를 실행해서 JWT토큰을 얻었습니다. 이걸 따로 적어두시면 됩니다.
그리고 wireshark를 설치합니다. wireshark 설치방법은 생략하도록 하겠습니다.
Wi-Fi를 사용하고 있다면 Wi-Fi: en0를 선택하고 바로 위에 있는 필터에 다음과 같이 입력합니다.
tcp port 50051
그리고 gRPC서버를 실행시키겠습니다.
git clone https://github.com/grpc/grpc-go.git
cd grpc-go/examples/helloworld
go run greeter_server/main.go
brew install grpcurl
grpcurl -plaintext \
-H "Authorization: Bearer <JWT토큰을 넣어주세요>" \
-d '{"name": "경석"}' \
localhost:50051 \
helloworld.Greeter/SayHello
위에서부터 순서대로 실행시키면 됩니다.
그리고 제대로 헤더가 압축되는 것을 보고싶으시다면 grpcurl을 여러번 실행하는 것을 추천드립니다.
그럼 wireshark에 어떻게 뜨는지 확인해보겠습니다.
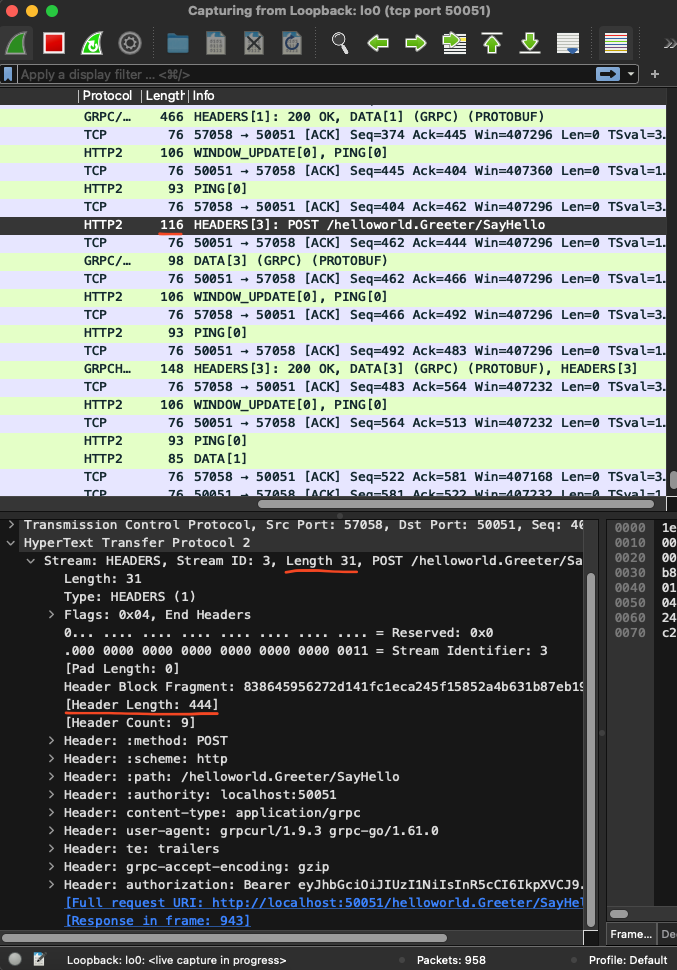
보시면 숫자가 세개 있는데 맨 위에서부터 실제 네트워크를 탄 헤더크기, 압축된 헤더 크기, 압축을 해제한 헤더 크기 이렇게입니다.
그럼 뭐가 진짜인가하면 첫번째가 실제로 네트워크로 전송되는 헤더 크기입니다. 즉, 116Bytes가 실제 네트워크로 전송된 헤더 크기입니다.
이제 wireshark의 포트를 8060으로 해줬습니다. 남는 포트 아무거나 쓰시면 됩니다. 저는 8080을 쓰고있어서 적당히 8060을 사용했습니다.
tcp port 8060
그리고 아래와 같은 명령어를 입력합니다.
python3 -m http.server 8060
이러면 간단한 http server가 생성됩니다. 그리고 아래와 같은 명령어로 해당 서버로 요청을 보내봅니다.
curl -v \
-H "Authorization: Bearer <JWT토큰을 넣어주세요>" \
http://localhost:8060
이것도 여러번 실행한 뒤 wireshark를 보면?

약간 연두색으로 되어있는게 실제 패킷이 이동한 것이고 첫번째가 요청, 두번째가 응답입니다. 즉, 요청헤더로 349Bytes를 보내고 응답으로 body 포함 1546Bytes를 받은겁니다.
그럼 헤더는 349Bytes네요.
아까 gRPC는 116Bytes였죠? REST API는 349Bytes입니다.
오우... 세배정도 차이가 나네요. 이게 쌓이고 쌓이면 정말 큰 차이가 벌어집니다. 네트워크 레이턴시에 큰 영향을 주죠.
보통 요청헤더에 큰 용량을 차지하는 JWT토큰을 추가하긴 했지만 확실히 큰 차이가 납니다.
Protobuf
위에서 헤더를 압축했다면 Protobuf는 굳이 따지자면 body를 압축한 것으로서 기존 HTTP/1.1은 JSON기반의 텍스트를 응답했다면 Protobuf는 바이너리를 응답하기에 컴퓨터가 더 잘 읽을 수 있어서 성능상 이점을 보입니다.
Protobuf의 주된 특징은 성능도 있지만 추상화가 장점인데요. 이 추상화가 어느정도의 추상화냐면 언어가 다른 두개의 서버가 통신할 때도 같은 포맷으로 통신할 수 있을 정도입니다.
아닌 동기통신에서 사용한다면 아마 로그인이 있을 것 같은데 억지로 예시를 만들어서 정리해보겠습니다. 주문, 결제, 상품, 알람으로 이어지는 비동기 통신은 Kafka로 진행한다고 가정하겠습니다.
만약 요청을 보내는 곳은 spring boot이고 응답을 보내주는 인증 서버는 node.js로 만들어졌다고 가정하겠습니다.
그럼 이 두개의 프로젝트에 똑같은 protobuf가 만들어져야합니다.
syntax = "proto3";
message LoginRequest {
string username = 1;
string password = 2;
}
message LoginResponse {
bool success = 1;
string token = 2;
}
파일 이름은 auth.proto로 하고 예제 코드는 생략하겠습니다.
그럼 spring boot에서 protobuf에 대한 구현체를 만들고 node.js에서 protobuf에 대한 구현체를 만들면 서로 다른 언어로 되어있지만 통신이 가능하게됩니다.
이정도의 추상화 덕분에 서로 언어가 달라도 서버간 통신이 용이해진다는 것이 큰 장점입니다. 거기에 요청과 응답을 바이너리로 받아서 성능이 올라간다는 것은 덤이구요.
멀티플렉싱
헤더와 바디를 압축했으니 이제 성능에 대해 본격적으로 이야기해볼까합니다.
멀티플렉싱이란 하나의 커넥션에서 여러개의 처리를 할 수 있는지 여부에 대한 것으로서 보통 HTTP/1.1에선 하나의 커넥션이 하나의 처리밖에 하지 못해 앞에 있는 요청이 끝나기 전까지 뒤의 요청이 처리를 할 수 없습니다.
하지만 HTTP/2에선 하나의 커넥션이 여러개의 처리를 동시에 할 수 있어서 속도가 굉장히 빠르다는 특징이 있습니다.
이를 예시로 들자면 카페에서 종업원에게 주문을 넣을 때 줄을 서서 주문을 넣는 것이 HTTP/1.1이라면 HTTP/2는 손님들이 종이에 자기가 원하는 음료를 적고 종업원에게 전달해주면 종업원이 빨리 끝나는 음료를 먼저 만들어서 만들어주는 것과 같습니다.
멀티플렉싱은 REST API와 gRPC의 차이이기도 하지만 HTTP/1.1과 HTTP/2의 차이이기 때문에 HTTP/1.1과 HTTP/2 서버를 두 대 띄워서 똑같이 실습을 해보겠습니다.
먼저 HTTP/1.1은 위에서 실습했던 서버를 그대로 재활용할 것입니다. 그리고 HTTP/2를 위한 서버를 만들어줘야합니다.
적당한 폴더를 하나 만들어주고 node.js로 간단한 HTTP/2서버를 만들어보겠습니다.
npm init -y
npm install http2-server
vim server.js
const http2 = require('http2');
const fs = require('fs');
const server = http2.createSecureServer({
key: fs.readFileSync('./cert/key.pem'),
cert: fs.readFileSync('./cert/cert.pem')
});
server.on('stream', (stream, headers) => {
stream.respond({
'content-type': 'text/plain',
':status': 200
});
stream.end('Hello over HTTP/2\n');
});
server.listen(8050, () => {
console.log('✅ HTTP/2 server running at https://localhost:8050');
});
이렇게 하면 서버는 준비 끝입니다. 그리고 보통 서버 성능 테스트는 wrk로 하는 것이 일반적이지만 wrk는 HTTP/2를 지원하지 않아서 h2load라는 것을 사용해서 HTTP/2를 실습해보겠습니다.
brew install wrk
brew install nghttp2
이렇게 적으면 우선 준비는 끝입니다. wrk로는 HTTP/1.1에 요청을, h2load로는 HTTP/2에 요청을 보내볼겁니다.
wrk -t4 -c1000 -d10s http://localhost:8060

먼저 HTTP/1.1의 결과입니다. 스레드는 4개 커넥션은 1000개를 10초동안 진행하여 약 8800개의 요청을 처리했네요.
평균 처리 시간은 14.66ms 최대 63.14ms를 기록했고 총 처리 시간은 10.06초입니다.
굳이 HTTP/1.1을 먼저 실습해본 이유가 있는데요. 초당 몇개정도의 요청이 가능한지 알아야 HTTP/2의 실습이 용이하기 때문입니다. 적당히 비슷한 8500개를 HTTP/2로 요청해보겠습니다.
h2load -n8500 -c100 -m100 https://localhost:8050
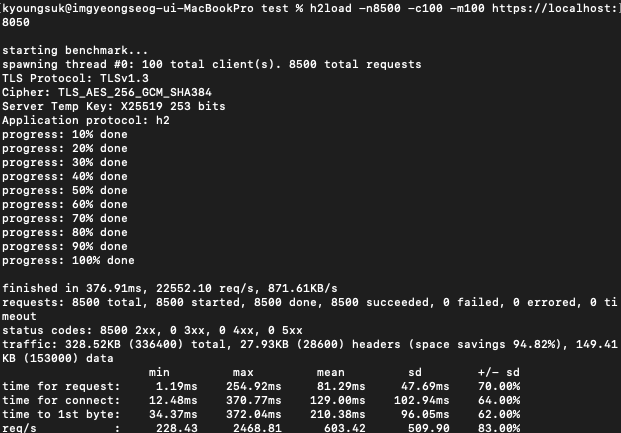
요청 8500개에 커넥션 100개 그리고 멀티플렉싱에 사용할 스트림 수를 100개로 만들어서 실행해보았습니다.
finished in에 보면 총 걸린 시간은 0.37초, 초당 2만2천개의 처리를 할 수 있는 성능이 나왔습니다. HTTP/1.1은 초당 880개정도의 요청을 처리할 수 있었던 것과 비교하면 엄청난 성능입니다.
레이턴시는 최소 1.19ms, 최대 254m.s로 HTTP/1.1에 비해 최대 레이턴시가 높은 것을 확인할 수 있었습니다. 중간 값은 81.29ms 평균 값은 47.69ms로 나왔습니다.
이번 실습으로 알 수 있었던 것은 HTTP/2는 요청이 많아지면 많아질수록 엄청난 장점을 보이지만 각각의 요청에 대한 응답은 느린 것으로 보여집니다. 즉, 사용자는 0.2초 정도 되는 레이턴시를 겪었지만 서버 입장에선 초당 2만2천개의 처리를 할 수 있기에 서버의 성능이 올라갔지만 클라이언트는 조금 느릴 수도 있다는 것이 단점이라면 단점이겠네요.
반면 HTTP/1.1은 서버가 처리할 수 있는 요청은 초당 880개정도로 HTTP/2에 비해 25배 낮은 성능을 보여줬지만 각각의 요청은 HTTP/2에 비해 빨랐습니다.
하지만 아무리 각각에 대한 요청이 HTTP/1.1이 빨랐다지만 서버의 성능을 판단할 때 중요한 것은 레이턴시뿐만 아니라 throughput이라고 부르는 처리량도 매우 중요한 지표이기에 확실히 HTTP/2가 월등히 성능이 좋은 것으로 보입니다.
마치며
성능에서 많이 후달리는 HTTP/1.1을 아직도 많이 사용하고 있는데 아마 그 이유가 바디에 바이너리로된 데이터를 보낸다는 것이 한 몫할 것같네요.
왜냐하면 서버간 통신이 아닌 클라이언트-서버간 통신이라면 클라이언트 즉, 브라우저가 읽을 수 있는 JSON같은 형태여야할텐데 바이너리는 클라이언트가 읽을 수 없기 때문이죠.
이번 포스팅에선 gRPC를 실습 위주로 테스트해보면서 왜 서버간 통신에서 gRPC를 사용할 수 밖에 없었는지에 대해서 정리해봤습니다.
긴 글 읽어주셔서 감사합니다. 오늘도 즐거운 하루 되세요!
'CS 지식 > 네트워크' 카테고리의 다른 글
| 패킷 한 조각의 모험 : 네트워크 속 비밀 이야기 (0) | 2024.11.18 |
|---|---|
| 네트워크 흐름제어와 혼잡제어 (Flow Control, Congestion Control) (0) | 2024.01.13 |
| TCP 3 way handshake (0) | 2023.03.25 |
| 검색창에 www.google.com 을 검색했을 때 (0) | 2023.03.23 |
| Stateless, Stateful 프로토콜 (0) | 2023.03.22 |