본 포스팅은 인프런의 정수원님의 스프링 배치 강의를 듣고 정리한 포스팅입니다. 더 자세한 내용은 강의를 참고해주세요.
ItemReader에는 다양한 구현체가 존재합니다. Flat File에 대한 구현체도 있고, XML을 읽는 구현체, json에서 읽는 구현체 다양한 구현체가 있습니다.
우리는 그 중에서 DB와 관련된 ItemReader에 대해 본격적으로 공부해볼 것입니다. 그 이유는 기본적으로 Flat File이나 XML이나 json을 읽는 것은 흔하지 않기 때문입니다.
따라서 우리는 이번 포스팅에서 ItemReader의 구현체 중 JbdcCursorItemReader, JpaCursorItemReader, JdbcPagingItemReader, JpaPagingItemReader 이 네가지 구현체에 대해서 알아보도록 하겠습니다.
그럼 시작해보겠습니다.
JdbcCursorItemReader
기본 개념
- Cursor 기반의 JDBC 구현체로서 ResultSet과 함께 사용되며 Datasource에서 Connection을 얻어와 SQL을 실행한다.
- Thread 안전성을 보장하지 않기 때문에 멀티 스레드 환경에서 사용할 경우 동시성 이슈가 발생한다. 때문에 동시성 이슈를 방지하기 위해 별도의 동기화 처리가 필요하다.
API

동시성 이슈가 발생한다는게 어떤 느낌이냐면
예를 들어서 Thread 1번이 DB의 데이터에 접근하기 위해 read() 메서드를 호출했습니다. 그렇게 커서 방식으로 첫번째 row 를 가져왔죠.
그 때 Thread 2번이 DB에 동시에 접근합니다. 그렇게 read() 메서드를 호출하면 이 때 동시성 문제가 발생합니다. 바로 똑같은 첫번째 row를 가져오게 되는겁니다.
이런 상황이 발생하지 않기 위해 동기화 처리를 별도로 해줘야 한다는 의미입니다.
작동 순서
- 맨 처음으로 Step이 ItemStream을 open() 메서드를 이용해 엽니다. 이 때 DB Connection과 PreparedStatement, ResultSet 까지 모두 객체를 생성합니다.
- 그 다음 JdbcCursorItemReader 에서 read() 메서드를 통해 객체를 하나씩 DB에서 읽습니다. 이 때 중간에 RowMapper가 ResultSet을 호출하고 DB에서 값을 하나씩 꺼내오는 중개역할을 합니다.
- 2번의 과정이 Chunk Size만큼 계속 반복됩니다.
- 마지막으로 Step이 ItemStream의 close() 메서드를 호출해 ResultSet, PreparedStatement, Connection을 역순으로 닫습니다.
사용 방법

이렇게 하나의 사이클이 완료됩니다. 이후 더 이상 읽을 데이터가 없을 때까지 Chunk Size만큼 반복해서 계속 돌아갑니다.
JpaCursorItemReader
기본 개념
- Spring Batch 4.3 버전부터 지원함
- Cursor 기반의 JPA 구현체로서 EntityManagerFactory 객체가 필요하며 쿼리는 JPQL을 사용한다.
API

동작 순서
JpaCursorItemReader는 JdbcCursorItemReader와 동작방식이 약간 다릅니다.
- 맨 처음 Step이 ItemStream을 open()메서드를 이용해 엽니다. 그리고 EntityManagerFactory를 가지고 EntityManager를 만듭니다. 그리고 JPQL을 Query로 만들어서 DB에 접근합니다. 그리고 해당되는 값들을 ResultStream에 담아놓습니다.
- 그 이후 JpaCursorItemReader 구현체에서 doRead() 메서드로 ResultStream에 접근해 Iterator로 데이터를 돌리면서 객체를 가져옵니다.
- 2번의 과정이 Chunk Size만큼 Streaming 방식으로 반복됩니다.
- 마지막으로 ItemStream을 close() 메서드로 호출해 EntityManager를 닫습니다.
JdbcCursorItemReader와 다른 점은 우선 ItemStream으로 객체들을 생성할 때 데이터를 전부 가져온다는 점이 있겠습니다.
next()를 호출해서 하나의 row씩 DB에 접근하는 Jdbc와 다르게 Jpa는 next()를 호출할 때 ResultStream에 접근해 Iterator로 데이터를 하나씩 가져옵니다.
그렇기 때문에 JpaCursorItemReader의 API에는 fetchSize를 설정할 수 있는 부분이 빠져있습니다. DB와 연결은 하지만 ResultSet이 DB와 연결하는 부분이 생략되어있기 때문에 그런것으로 추정됩니다.
사용 방법
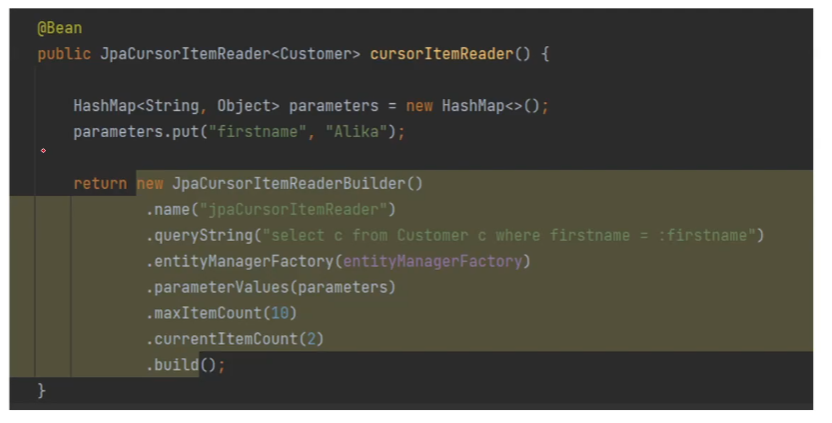
보통은 maxItemCount와 currentItemCount 가 빠져있는 형태로 많이 만듭니다.
JdbcPagingItemReader
기본 개념
- Paging 기반의 JDBC 구현체로서 쿼리에 시작 행 번호 (offset) 와 페이지에서 반환 할 행 수 (limit) 를 정해서 SQL을 실행한다.
- 스프링 배치에서 offset과 limit을 PageSize에 맞게 자동으로 생성해 주며 페이징 단위로 데이터를 조회할 때마다 새로운 쿼리가 실행된다.
- 페이지마다 새로운 쿼리를 실행하기 때문에 페이징 시 결과 데이터의 순서가 보장될 수 있도록 order by 구문이 작성되도록 한다.
- 멀티 스레드 환경에서 Thread 안정성을 보장하기 때문에 별도의 동기화를 할 필요가 없다.
PagingQueryProvider
- 쿼리 실행에 필요한 쿼리문을 ItemReader에게 제공하는 클래스
- 데이터베이스마다 페이징 전략이 다르기 때문에 각 데이터베이스 유형마다 다른 PagingQueryProvider를 사용한다.
- select 절, from 절, sortKey는 필수로 설정해야 하며 where, group by 절은 필수가 아니다.

API

동작 순서
- 첫 번째로 Step이 ItemStream을 open() 메서드를 이용해 열어서 ExecutionContext를 업데이트 합니다.
- 그 다음 Step이 read() 메서드를 이용해 JdbcPagingItemReader에 접근합니다. 그리고 doReadPage()메서드를 이용해 JdbcTemplate을 가지고 쿼리를 날립니다.
- 쿼리에 해당하는 결과를 ResultSet에 담아서 DB에서 next() 메서드를 호출하며 결괏값을 rowMapper를 이용해 List에 담습니다. 그리고 해당 List를 return 합니다.
- 3번의 과정이 ChunkSize만큼 반복됩니다.
- 마지막으로 ItemStream을 close()메서드로 호출해 페이징을 닫습니다.
사용 방법
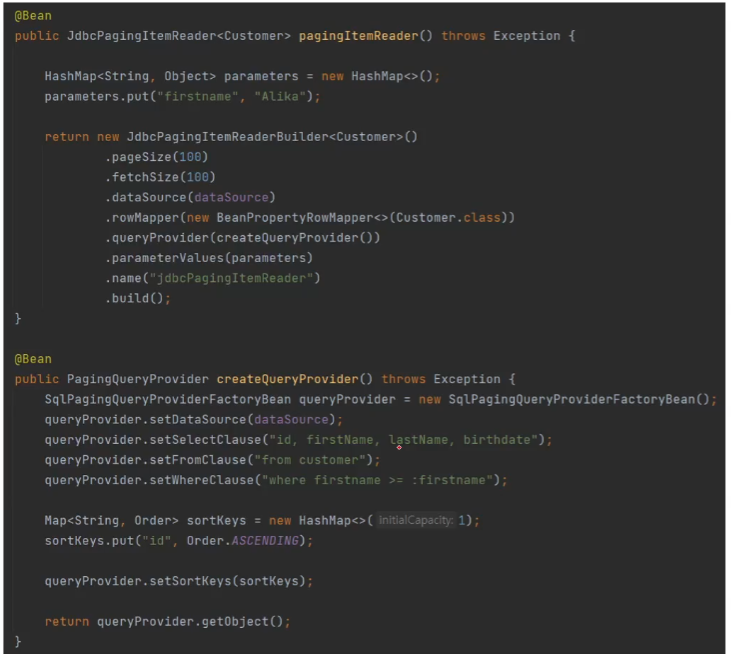
PagingItemReader는 스레드 세이프하다고 앞에서 설명해드렸는데요 이 부분이 어떻게 구현되어 있을지 한번 확인해보도록 하겠습니다.
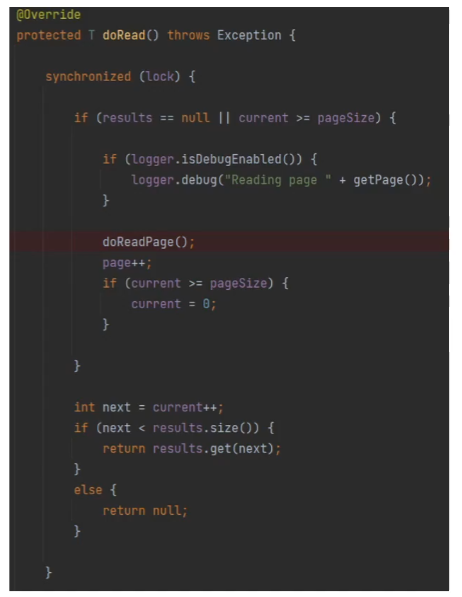
synchronized 라는 키워드를 통해 멀티 스레드에서도 안전하게 처리할 수 있도록 처리가 되어있는 모습입니다.
synchronized에 대해 간단하게 설명하자면 여러개의 스레드가 해당 메서드에 접근하더라도 synchronized가 붙어있는 메서드는 하나의 스레드만 들어와서 처리할 수 있습니다.
하나의 스레드가 해당 메서드가 처리될 때까지 lock을 가지고 있고 처리가 완료되면 lock이 풀리는 구조이기 때문에 조금이라도 뒤에 도착한 스레드는 해당 메서드에 접근할 수 없습니다.
JpaPagingItemReader
기본 개념
- Paging 기반의 JPA 구현체로서 EntityManagerFactory 객체가 필요하며 쿼리는 JPQL을 사용한다.
API

동작 순서
- 첫 번째로 ItemStream에서 oepn()메서드를 이용해 EntityManager를 생성합니다.
- JpapagingItemReader의 read()메서드를 이용해 EntityManager를 참조해서 Query를 만듭니다. 이 Query는 ResultList를 만들어서 반환합니다.
- 2번의 과정이 ChunkSize만큼 반복됩니다.
- 마지막으로 ItemStream에서 EntityManager를 닫습니다.
사용 방법

정리
여기까지 JdbcCursorItemReader, JpaCursorItemReader, JdbcPagingItemReader, JpaPagingItemReader 이렇게 네가지의 ItemReader에 대해서 알아봤습니다.
JPA의 API들이 간단하고 단순해서 사용하기 더 용이해 보이는 장점이 있는 것 같습니다. JPA를 사용할 줄 안다면 JPA관련 ItemReader들이 좀 더 쉽게 접근할 수 있을 것 같습니다.
Cursor 기반의 ItemReader와 Paging 기반의 ItemReader의 차이점에 대해서 궁금하신 분은 아래의 링크에서 확인할 수 있습니다.
https://coding-review.tistory.com/181
스프링 배치 CursorItemReader vs PagingItemReader
스프링 배치에서는 각기 다양한 ItemReader를 제공하는데 그 중 CursorItemReader 와 PagingItemReader는 언뜻 보기에 비슷해 보이고 실제로도 하는 일이 비슷합니다. 그래서 이번 포스팅에선 이 둘의 차이점
coding-review.tistory.com
JDBC나 JPA 모두 쿼리를 직접 적어야 한다는 부담 때문에 사용하기 조금 꺼려질 수도 있습니다. 그럴때는 QuerydslPagingItemReader를 따로 만들어서 해당 문제를 해결하는 방법이 있습니다. 이 내용에 대해서는 향로(jojoldu)님의 "스프링 배치와 Querydsl" 포스팅을 참고해주시면 감사하겠습니다.
https://techblog.woowahan.com/2662/
Spring Batch와 Querydsl | 우아한형제들 기술블로그
{{item.name}} Spring Batch와 QuerydslItemReader 안녕하세요 우아한형제들 정산시스템팀 이동욱입니다. 올해는 무슨 글을 기술 블로그에 쓸까 고민하다가, 1월초까지 생각했던 것은 팀에 관련된 주제였습
techblog.woowahan.com
여기까지 긴 글 읽어주셔서 감사합니다. 다음엔 ItemWriter 심화에 대해 포스팅해보도록 하겠습니다.
'Spring > Spring Batch' 카테고리의 다른 글
| 멀티 스레드 환경에서의 스프링 배치 (개요) (0) | 2022.10.12 |
|---|---|
| Chunk 지향 처리 : ItemWriter (심화) (0) | 2022.10.11 |
| Chunk 지향 처리 : ItemReader, ItemProcessor, ItemWriter 개요 (0) | 2022.10.04 |
| 스프링 배치 키워드 정리 (0) | 2022.10.03 |
| Chunk 지향 처리 : Chunk, ChunkProvider, ChunkProcessor (0) | 2022.10.01 |