MySQL은 다양한 레플리케이션 전략을 가지고 있습니다. 동기, 반동기, 비동기 이렇게 세 가지 전략을 가지고 있죠. 그 중에서 Orchestrator는 비동기 레플리케이션을 구현할 수 있게 해주는 서드파티 툴입니다.
이번 포스팅에선 Orchestrator가 어떻게 자동으로 장애회복을 할 수 있는지, 어떻게 레플리케이션을 구축할 수 있는지에 대해서 공부해보고 정리해봤습니다.
Orchestrator가 뭐야?
Orchestrator는 MySQL진영의 레플리케이션을 구축하기위한 서드파티 툴입니다. Orchestrator는 GUI로 MySQL서버들을 관리할 수 있다는 것만으로도 쓸만한 이유가 되는 툴인데요.
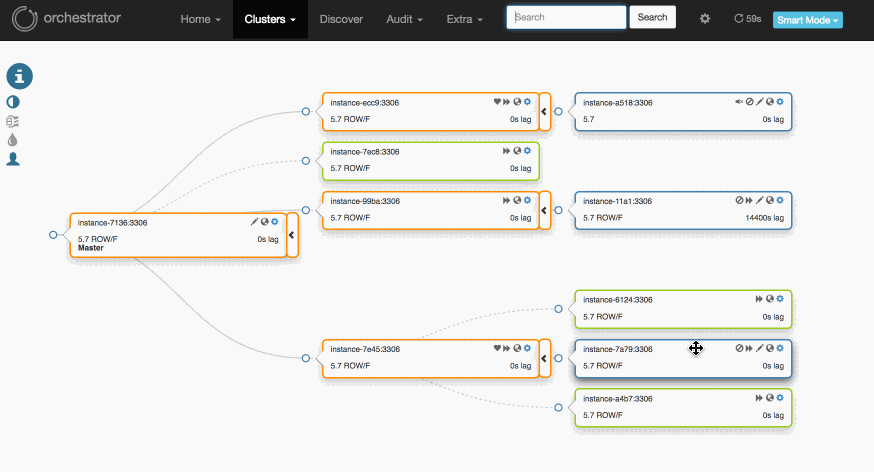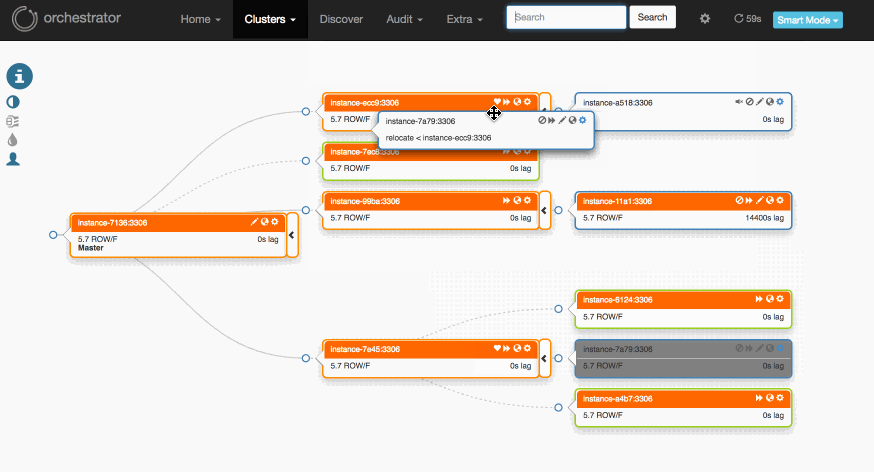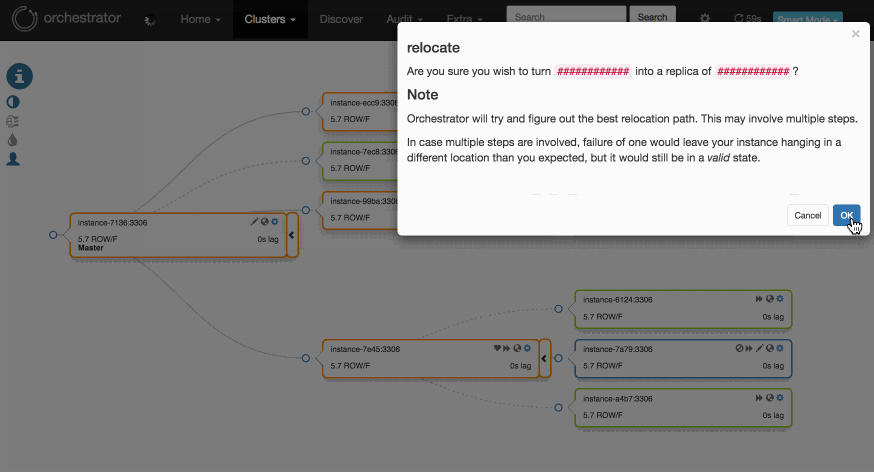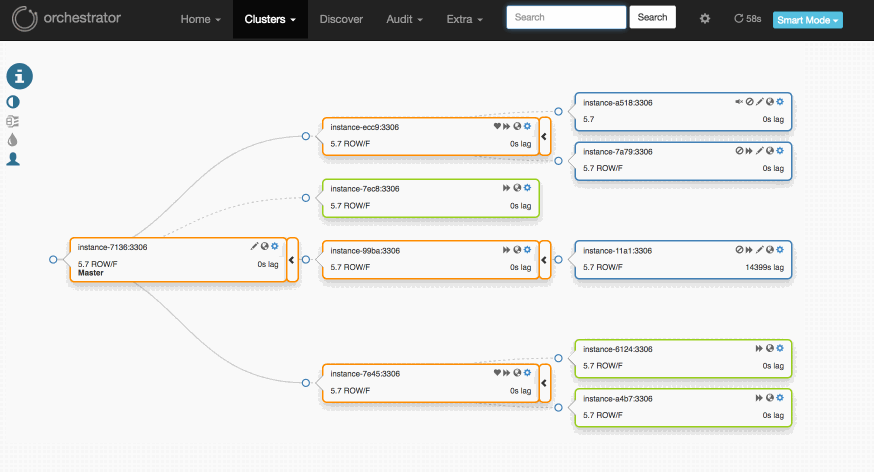
이렇게 노드의 위치를 옮겨가면서 노드들을 관리할 수 있습니다.
노드를 끌어다 마스터노드로 놓으면 이 노드가 마스터 노드로 승격이 되고 트리구조의 레플리케이션으로 관리하기가 쉽다고 하네요. 제가 현업에서 사용한 것은 아니라서 진짜 사용하기 쉬운지는 모르겠습니다.
Orchestrator의 Automatic Failover
Orchestrator는 자동으로 장애를 회복할 수 있는 토폴로지를 제공하고 있습니다. 토폴로지란 전자기공학에서 논리회로를 이야기하는 것으로서 컴퓨터공학에선 논리 아키텍처를 매칭할 수 있습니다.
위에서 보여드렸던 대로 수동으로 장애를 회복하는 것은 기능으로서 제공하는 것이지만 이를 실전에서 사용하는 것은 상상하기 어렵습니다. 때문에 Orchestrator는 자동으로 장애회복을 하는 토폴로지가 자주 쓰일텐데 어떻게 자동으로 장애를 회복하는 것일까요?
우선 Orchestrator가 마스터 노드가 죽었는지 살았는지 확인하는 방법은 여러개가 있을 수 있습니다.
- 마스터 노드의 3306포트가 열려있는지 확인한다.
- 마스터 노드로 간단한 쿼리를 날려본다. (SELECT 1 FROM DUAL)
- 실제 데이터를 가져오는 쿼리를 날려본다.
1번에서 3번으로 갈 수록 지속적으로 수행하기엔 힘들지만 죽었는지 살았는지 확실하게 아는 방법입니다.
하지만 이런 방법들은 공통적인 문제를 가지고 있습니다.
바로 Split Brain 현상에 대한 대책이 없다는 것인데요. Split Brain은 아래의 링크에 자세히 설명되어있으니 참고해주시기 바랍니다!
https://coding-review.tistory.com/542
나는 왜 Redis Cluster 대신 Redis Sentinel을 사용하였는가.
이번 포스팅에선 Redis Cluster에 대해서 깊이있게 공부해볼겸 왜 제가 Redis Cluster 대신 Redis Sentinel을 사용하게 되었는지 정리해보는 시간을 가져볼까합니다. Redis ClusterRedis Cluster는 Redis Sentinel의
coding-review.tistory.com
이 Split Brain 현상때문에 Orchestrator는 독특한 방식을 사용합니다. 바로 모든 MySQL노드들과 연결되어있다는 장점을 십분 발휘한 것인데요.
네트워크 단절로 발생한 Split Brain을 방지하기 위해서는 슬레이브 노드들이 마스터 노드와 정상적인 통신을 하고 있는지 확인하면 됩니다.
모든 슬레이브 노드 중 하나라도 마스터 노드와 통신하고 있다면 마스터 노드는 죽은 것이 아니기 때문에 슬레이브 노드를 마스터로 승격시키지 않습니다.
하지만 모든 슬레이브 노드가 마스터와 연결이 되어있지 않다면 그때 진짜 마스터 노드가 죽었다는 것이기 때문에 슬레이브 노드 중 하나를 승격시키게 됩니다.
그래도 이 방법이 완벽한 방법은 아니다.
이렇게 자동으로 승격시키는 과정이 확실히 Split Brain을 방지하는 대책으로서 작용하지만 완벽한 방법은 아닙니다.
왜냐하면 이 방식은 슬레이브 노드가 마스터로의 승격이 늦어지기 때문입니다. 마스터 노드와 연결된 모든 슬레이브 노드들의 상태를 확인해야 하기 때문에 마스터로의 승격이 늦어질 수 있습니다.
이는 데이터 유실로 이어질 수 있고 만약 데이터 쓰기 연산이 많은 애플리케이션일수록 이 상황은 큰 문제가 됩니다.
이를 해결하기 위해서는 Orchestrator의 Emergency Detect Failure 설정으로 해결할 수 있습니다. 하지만 이 방법은 앞서 언급했듯이 Split Brain을 야기할 수 있기 때문에 조심해서 사용해야 합니다.
또한, Automatic Failover도 만능은 아니다.
Orchestrator가 자동으로 장애를 회복할 수 있다고 하지만 Orchestrator는 모든 노드들에 대한 자세한 정보를 가지고 있지 않습니다. 이는 노드들의 메타데이터를 가지고 있지 않다고 해석할 수도 있는데 이점은 자동으로 장애를 회복하는 과정에서 문제가 발생할 수 있습니다.
자세한 정보를 가지고 있지 않기 때문에 마스터 노드의 장애를 인식하는 과정에서 확실한 정보가 없어 잘못된 마스터로의 승격을 야기할 수 있기 때문이죠.
이는 단순히 Orchestrator가 정확한 정보를 가지고 있지 않기 때문에 발생하는 문제입니다.
때문에 Orchestrator의 공식문서에서는 Orchestrator와 Vitess를 같이 사용할 것을 권고하고 있습니다.
그럼 Vitess는 뭔가요?
Orchestrator의 단점을 메워준다. Vitess
Vitess (비-테스 라고 발음합니다.) 는 MySQL노드들의 메타데이터를 가지고 MySQL을 조금 더 잘 사용할 수 있도록 제공해주는 서드파티 툴입니다.
Orchestrator는 MySQL의 정확한 메타데이터를 가지고 있지 않지만 Vitess는 정확한 MySQL노드의 메타데이터를 가지고 있습니다. 때문에 Orchestrator는 마스터노드로의 승격에 필요한 정보를 주고 받을 수 있습니다.
여기서 Vitess에 대해서 잠깐 정리하고 넘어가자면
Goroutine으로 경량화된 커넥션을 맺을 수 있음
Vitess는 Go로 개발된 MySQL서드파티 툴입니다. MySQL의 커넥션을 한번 맺으려면 최대 3MB의 메모리가 필요한데 이는 커넥션 풀을 사용한다고 하더라도 많은 리소스를 사용하는 것으로써 이 경량화된 스레드로 경량화된 커넥션을 맺을 수 있어 커넥션에 필요한 리소스를 최소화 할 수 있습니다.
쿼리 재사용 가능
MySQL은 같은 쿼리를 재사용할 때 최적화된 로직을 가지고 있지만 Vitess는 이보다 더 최적화된 SQL parser가 있어서 똑같은 쿼리를 재사용할 때 내부적으로 최적화하여 쿼리에 대한 성능을 끌어올렸습니다.
이는 동일한 쿼리가 반복적으로 발생되는 일반적인 애플리케이션 특성상 성능상 이점을 얻을 수 있죠.
샤딩 제공
일반적인 바닐라 MySQL에서는 제공하지 않는 샤딩을 제공하면서 데이터를 효과적으로 분리하여 분산시스템에서도 적절히 사용할 수 있는 솔루션을 제공해줍니다.
이런 샤딩은 수평으로 확장할 때 유용하게 사용된다는 장점이 있습니다. 하지만 복잡성이 올라가기 때문에 조심히 사용해야하는 기능 중 하나이죠.
클러스터링 제공
HA를 위해 클러스터링 방식으로 데이터베이스의 가용성을 높였으며 이런 특징은 MySQL노드를 안정적으로 운영할 수 있게 해줍니다.
하지만 치명적인 단점이 있다.
Vitess의 이런 장점에도 문제는 Multiple Writable Primary를 엄하게 금지하고 있다는 것입니다. 즉, 마스터-마스터 레플리케이션을 금지하고 있다는 것입니다.
수직적인 레플리케이션 토폴로지를 가지고 있어서 마스터-마스터간 레플리케이션이 불가능해 쓰기 부하가 심하게 걸린다는 단점이 있습니다.
그렇기 때문에! Orchestrator와 협업이 빛나는 퍼포먼스를 이뤄낼 수 있습니다.
Orchestrator, Vitess 크로스!!
Orchestrator는 MySQL노드의 자세한 메타데이터를 가지고 있지 않고, Vitess는 마스터-마스터 레플리케이션이 불가능하기 때문에 이 둘의 단점을 완벽하게 보완해주는 관계라고 할 수 있습니다.
Orchestrator는 마스터로의 승격을 위해 Vitess의 메타데이터를 기반으로 더 확실한 승격을 할 수 있고, Vitess는 마스터-마스터간 레플리케이션으로 쓰기 부하를 효과적으로 분산시킬 수 있습니다.
이런 특징 때문일까요? Vitess 공식 문서에서는 Orchestrator와 Vitess를 합친 VTOrc라는 기능을 소개하고 있습니다.
이 둘은 서로가 서로를 사용하긴 하지만 종속적인 관계는 아닙니다. 둘은 협력관계일 뿐이죠.
하지만 이 둘이 협업하면서 꼬이게 되는 상황도 발생하기도 합니다.
Orchestrator가 완전히 동작하고 있는 레플리케이션 토폴로지를 사용하고 있을 때 (쓰기 전용 마스터노드와 읽기 전용 레플리카), Orchestrator가 마스터노드로 인식하고 있는 것을 Vitess는 슬레이브노드로 인식하고 Orchestrator가 슬레이브노드로 인식하고 있는 것을 Vitess가 마스터노드로 인식하는 상황입니다.
이런 흥미로운 상황은 이전에 실패한 Automatic Failover 프로세스가 조기에 종료되었을 때 발생할 수 있습니다. 이 경우 Orchestrator는 실제로 올바른 서버를 새로운 마스터노드로 승격시키고, 가짜 마스터노드를 레플리카로 강등하기위해 Graceful-Takeover (Vitess에선 Planned-Reparent라는 용어를 쓰더군요) 를 수행합니다.
때문에, 이런 의도치않은 상황에서도 Orchestrator가 자신의 레플리케이션 토폴로지를 만족시키기위해 뒷단에서 열심히 일하고 있는 모습을 볼 수 있습니다.
마치며
MySQL의 생태계를 공부하기 전에 Redis, PostgreSQL의 생태계를 먼저 공부하다보니 신선한 경험을 할 수 있었습니다. 제 본진이 MySQL진영인데 MySQL에 대해서 아는게 별로 없었다는 생각때문에 지금이라도 열심히 공부해야겠다는 생각을 했습니다.
MySQL진영도 꽤나 흥미로운 기술들이 많네요. 역시 데이터베이스 공부는 재밌습니다.
긴 글 읽어주셔서 감사합니다. 오늘도 즐거운 하루 되세요!
출처
https://planetscale.com/blog/orchestrator-failure-detection
Orchestrator failure detection and recovery: New Beginnings — PlanetScale
How the new integration adds new failure detection and recovery scenarios making orchestrator’s operation goal-oriented.
planetscale.com
https://vitess.io/docs/19.0/overview/whatisvitess/
Vitess | What Is Vitess
Vitess is a database solution for deploying, scaling and managing large clusters of open-source database instances. It currently supports MySQL and Percona Server for MySQL. It's architected to run as effectively in a public or private cloud architecture a
vitess.io
https://vitess.io/blog/2022-09-21-vtorc-vitess-native-orchestrator/
Vitess | VTOrc: Vitess-native Orchestrator
The differences between VTOrc and Orchestrator
vitess.io
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| MySQL 트랜잭션 로그 추적 with 스프링 (0) | 2024.11.26 |
|---|---|
| MySQL에 사는 유령 (0) | 2024.11.09 |
| 나는 왜 Redis Cluster 대신 Redis Sentinel을 사용하였는가. (0) | 2024.08.12 |
| PostgreSQL이 WAL (Write Ahead Log) 를 활용하는 방법 (0) | 2024.07.24 |
| 데이터베이스 조인 연산은 성능에 영향을 줄까? 안줄까? (0) | 2024.07.22 |