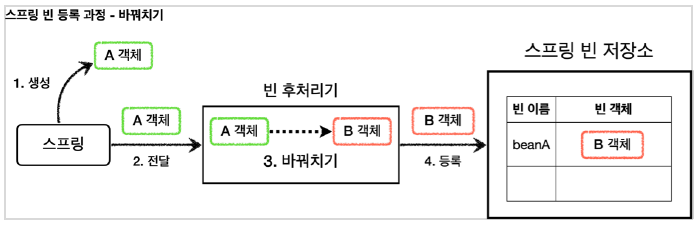
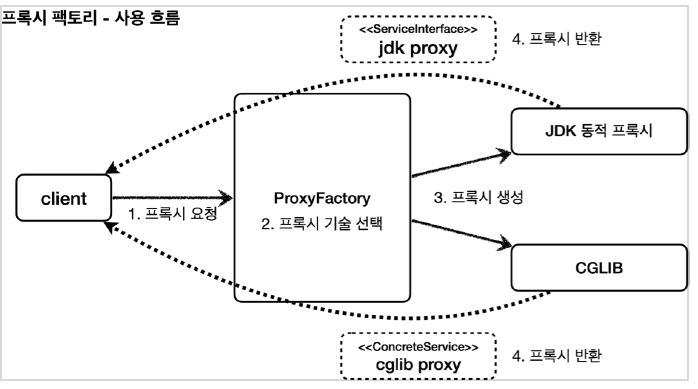
이 포스팅은 인프런 김영한 님의 실전! Querydsl 편을 보고 각색한 포스팅입니다. 자세한 내용은 강의를 확인해주세요 QueryDSL 시작하기 먼저 QueryDSL을 시작하기 위해선 gradle에서 설정을 해줘야한다. //querydsl 추가 buildscript { ext { queryDslVersion = "5.0.0" } } plugins { id 'org.springframework.boot' version '2.6.3' id 'io.spring.dependency-management' version '1.0.11.RELEASE' id 'java' id 'war' //querydsl 추가 id "com.ewerk.gradle.plugins.querydsl" version "1.0.10" } g..